SCISPOT (YC S21) INTERNSHIP
Building a smart data import tool for scientists
Context
Scispot (YC S21) is a early-stage startup that builds tools to accelerate scientific research discovery in healthcare.
Scispot has helped over 100+ clinical diagnostic labs document their lab samples, track experiment results and conduct analysis.
Time
2.5 weeks
Role
Product Manager/Designer (Me)
Software Engineer
CPO
Software Engineer
CPO
Constraints
Fast turn-around time
No UX testing
No UX testing
User group
Scispot is a B2B platform that serves clinics and labs.
Clinics
Patients book appointments to get check-ups.
Diagnostic labs
Scientists run test result experiments.
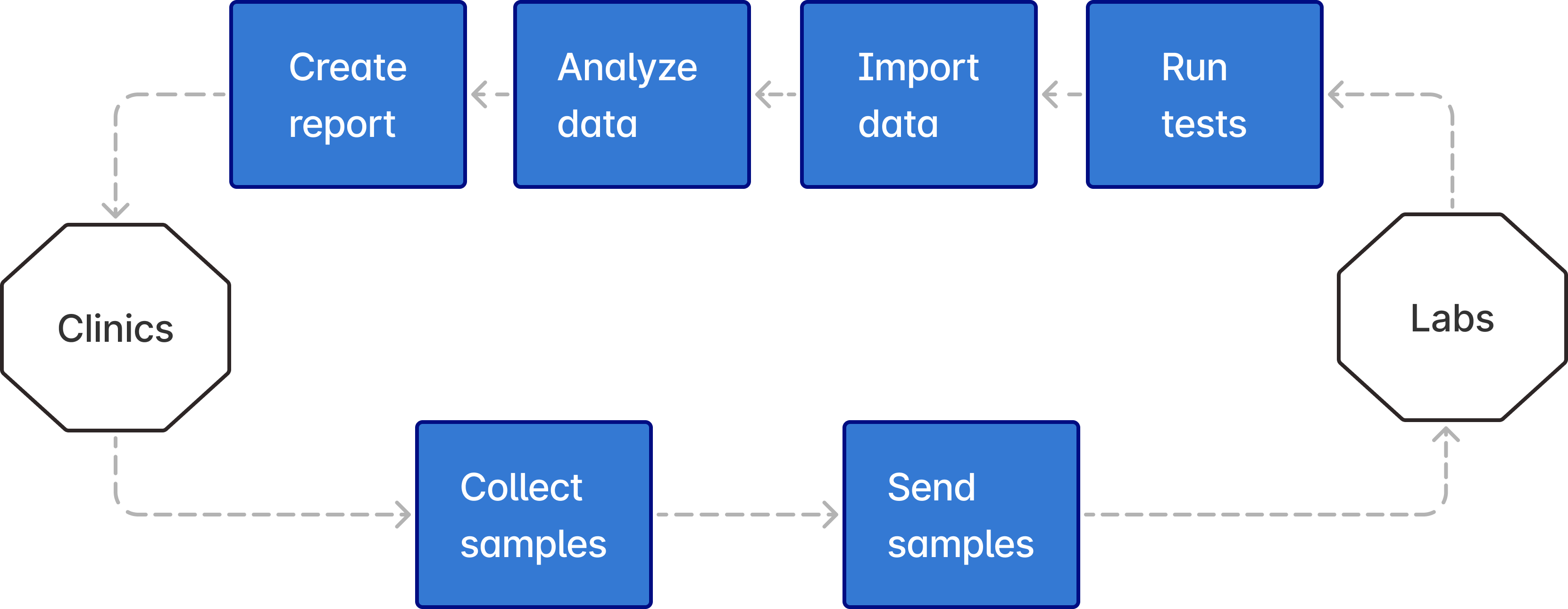
How do clinics work with labs?
Clinics are responsible for collecting various patient samples, including blood, urine, and skin. These samples are subsequently forwarded to diagnostic laboratories, where a series of tests are conducted. The resulting data is then imported back into Scispot for comprehensive analysis and used to generate a test level report.
What is labsheets?
Labsheets is a spreadsheet tool where scientists consolidate their sample data. Scientists store sample data such as ID, expiry date, sample type, quantity into columns with data types. The data types are text, number, date and link.
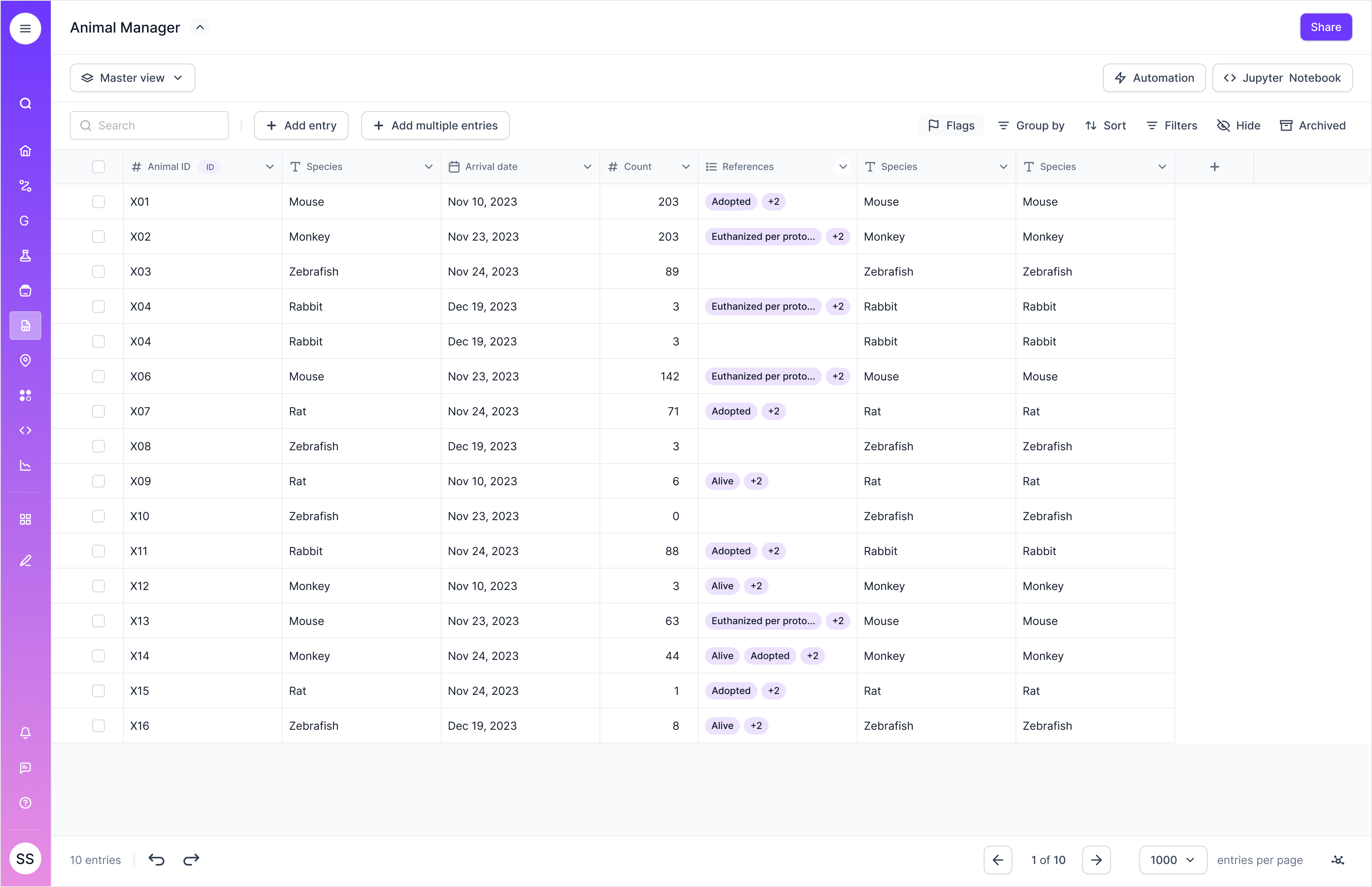
Uh-oh!
Scientists are making CSV imports into labsheets with missing data.
My team was being flooded with 100+ email complaints from customers about incomplete data in their labsheets.

The Problem
Scientists cannot map their CSV columns due to data type incompatibilities with the existing columns in their lab sheet.
Why is this important?
If scientists cannot import their scientific data, labs cannot generate a test level report for their patients.
.png)
My Impact
I designed a new data import tool within 5 days.
Scispot was at risk of losing high-value lab customers if this was not fixed immediately.
V1 shipped to 100+ labs in a week
Cut down import time by 30%
Current State
I interviewed 3 scientists to understand why imports were failing.
I wanted to understand where scientists are getting stuck in the user flow, why are they mapping their columns wrong and why they are experiencing data import issues.
.png)
After conducting research, I identified three main issues.
I went through the import csv process, audited the flow, and found the import flow to be incredibly manual and time consumping.
CURRENT PROCESS
Challenge #1: Reducing user flow friction
The current import flow is messy and time-consuming.
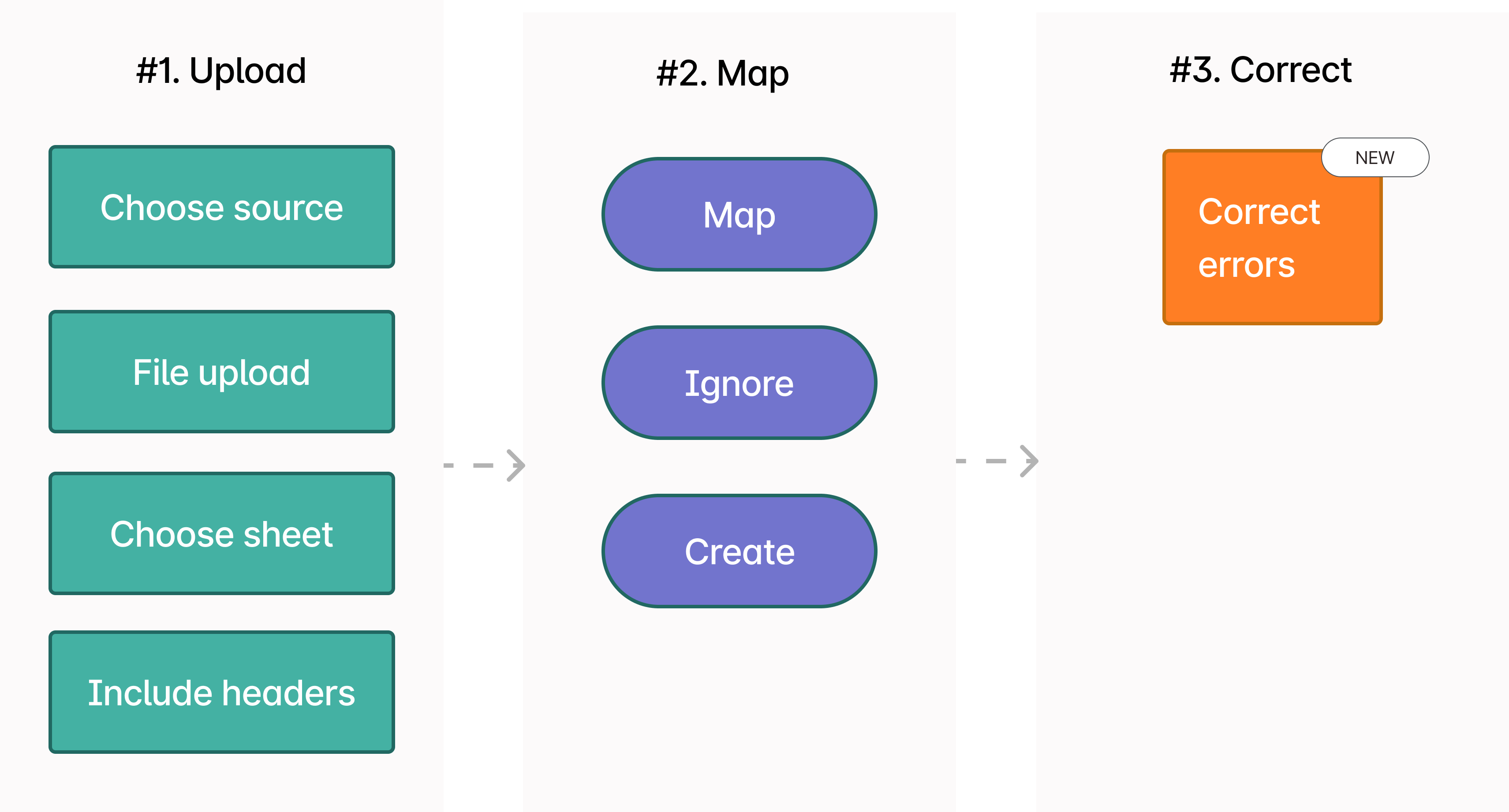
All the steps are presented as individual modals. I grouped the steps into stages, cutting down the number of steps from 7 to 3.
BEFORE
Individual steps
- 7 disjointed modal steps adds user friction
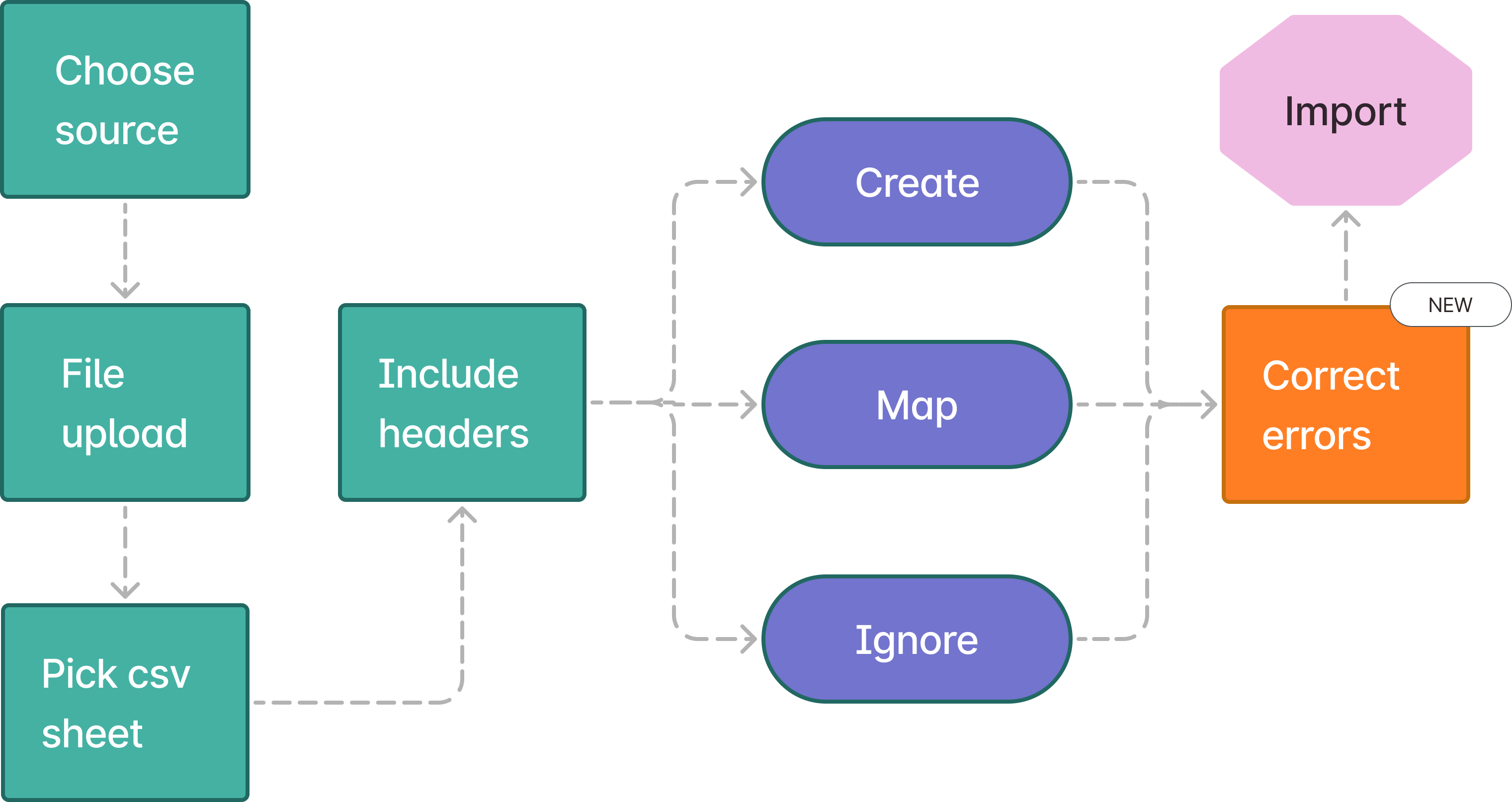
AFTER
Grouped page steps
- Reduce the number of screens from 7 to 3
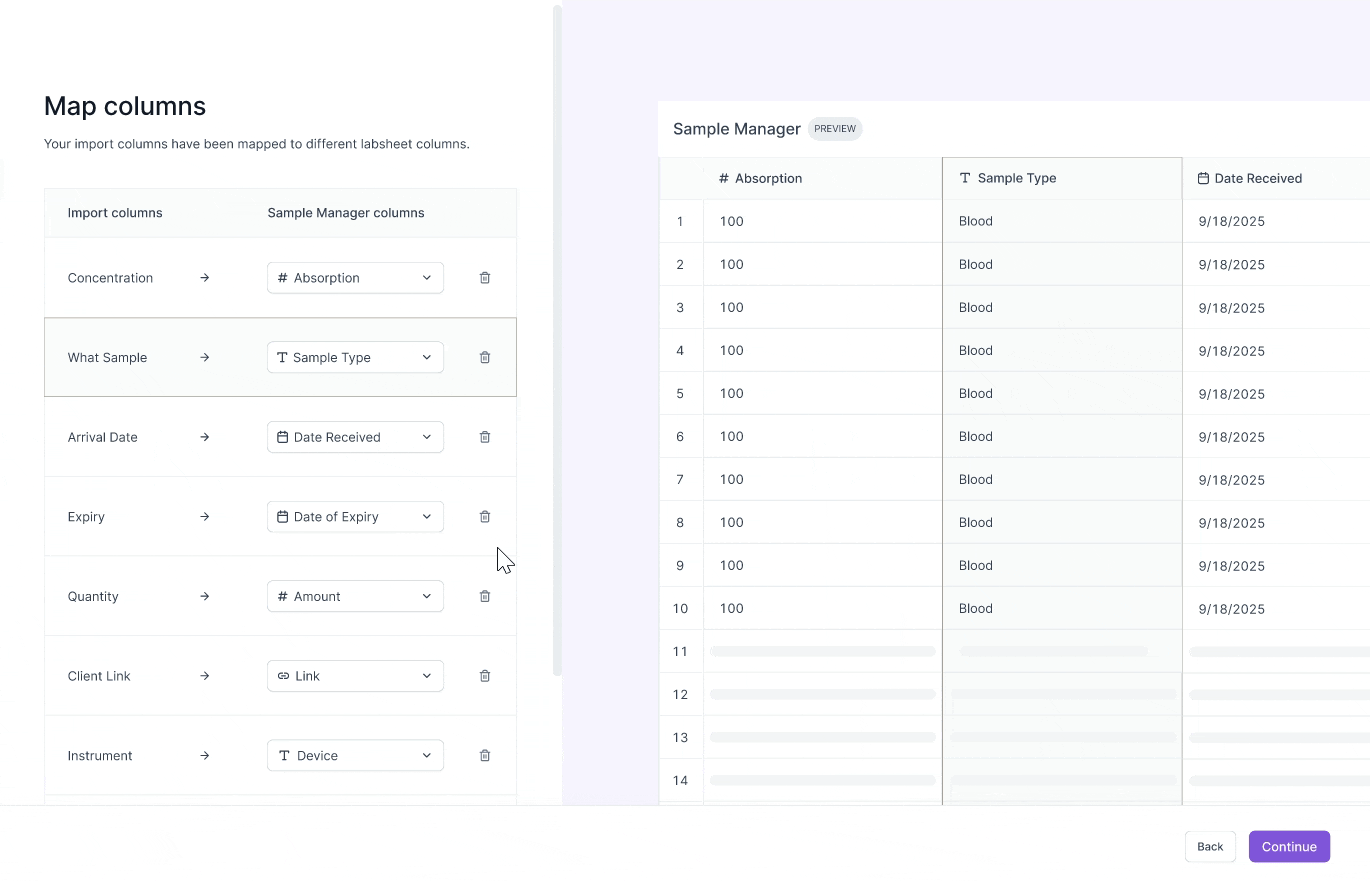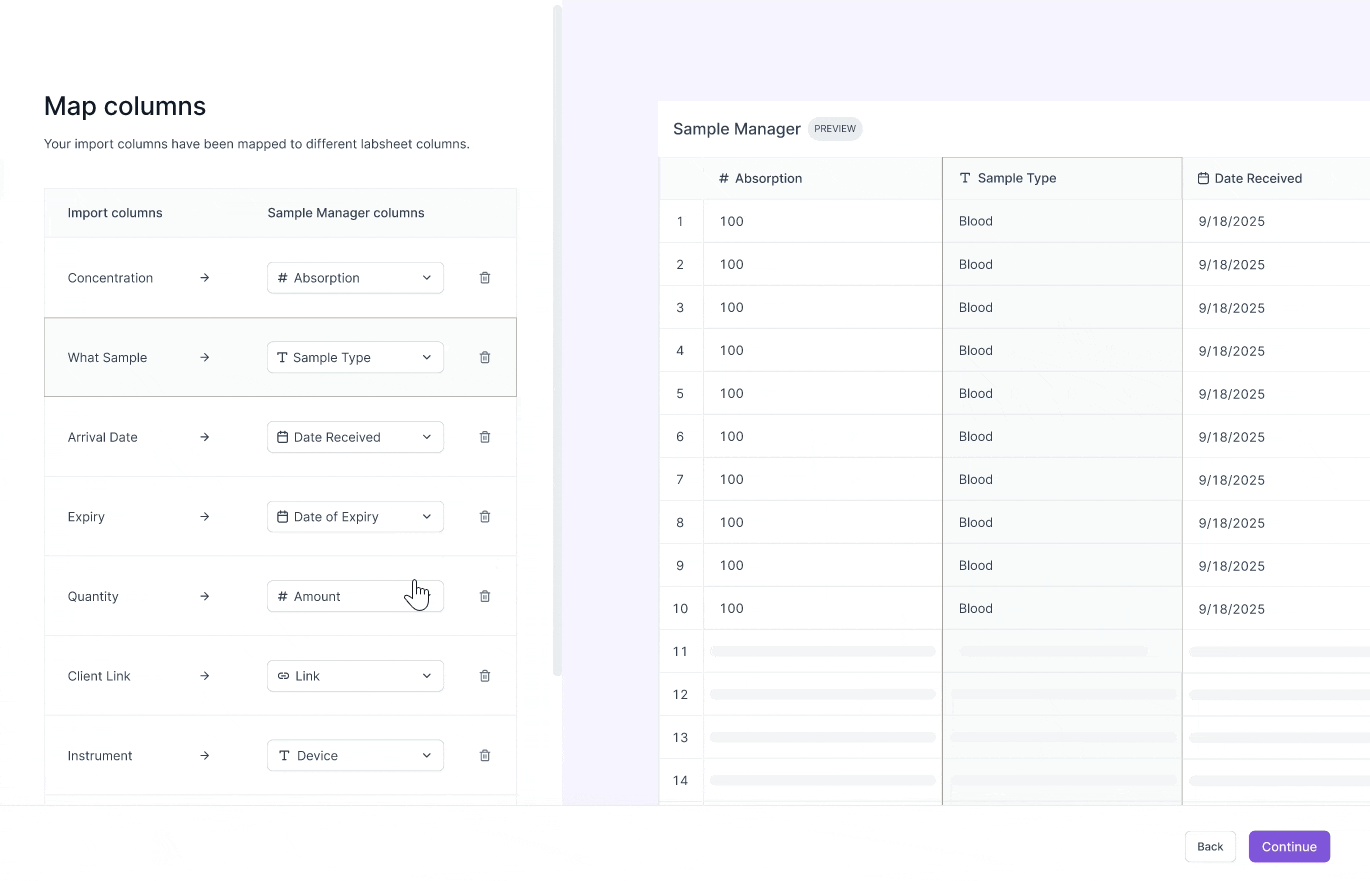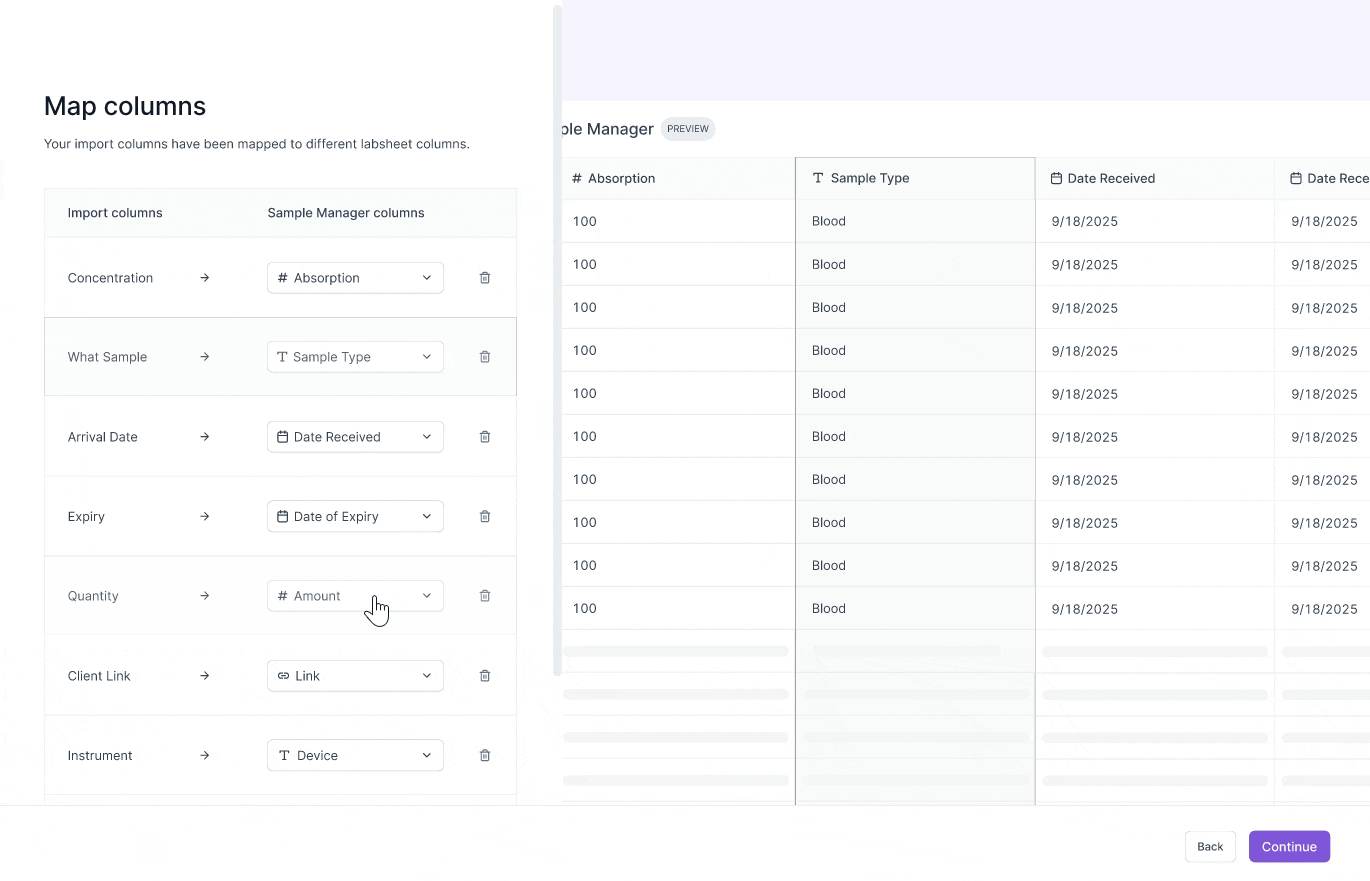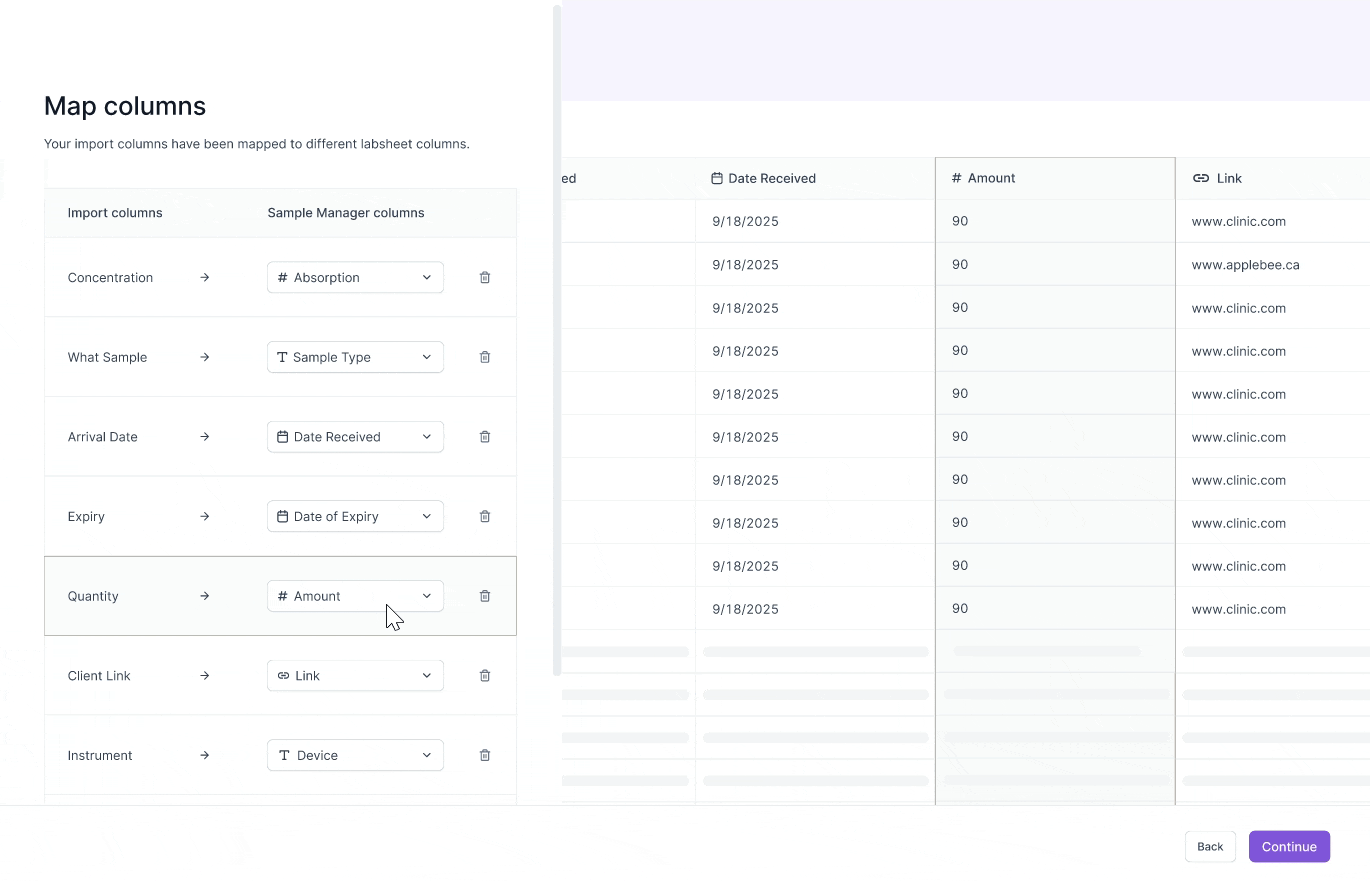
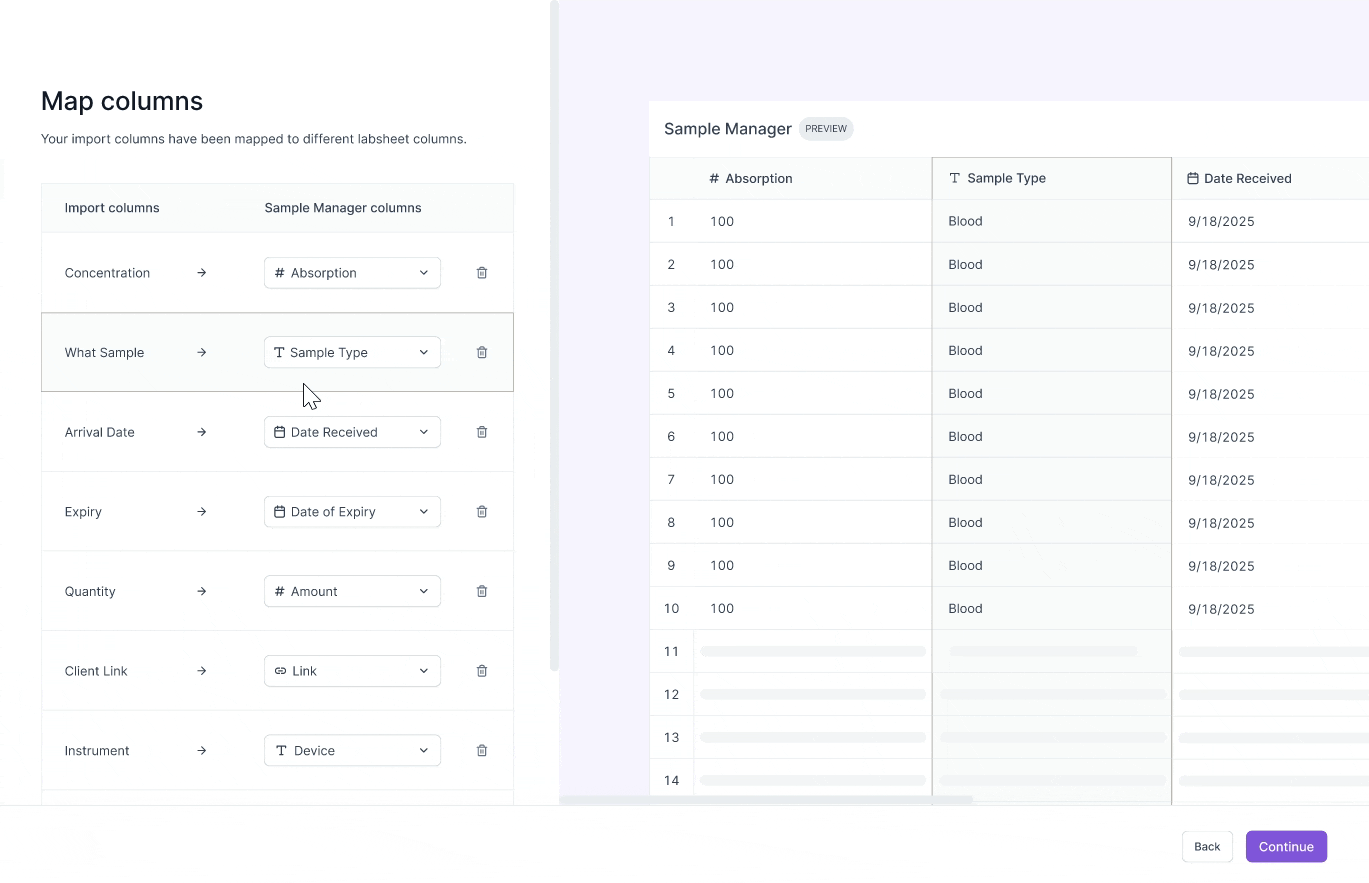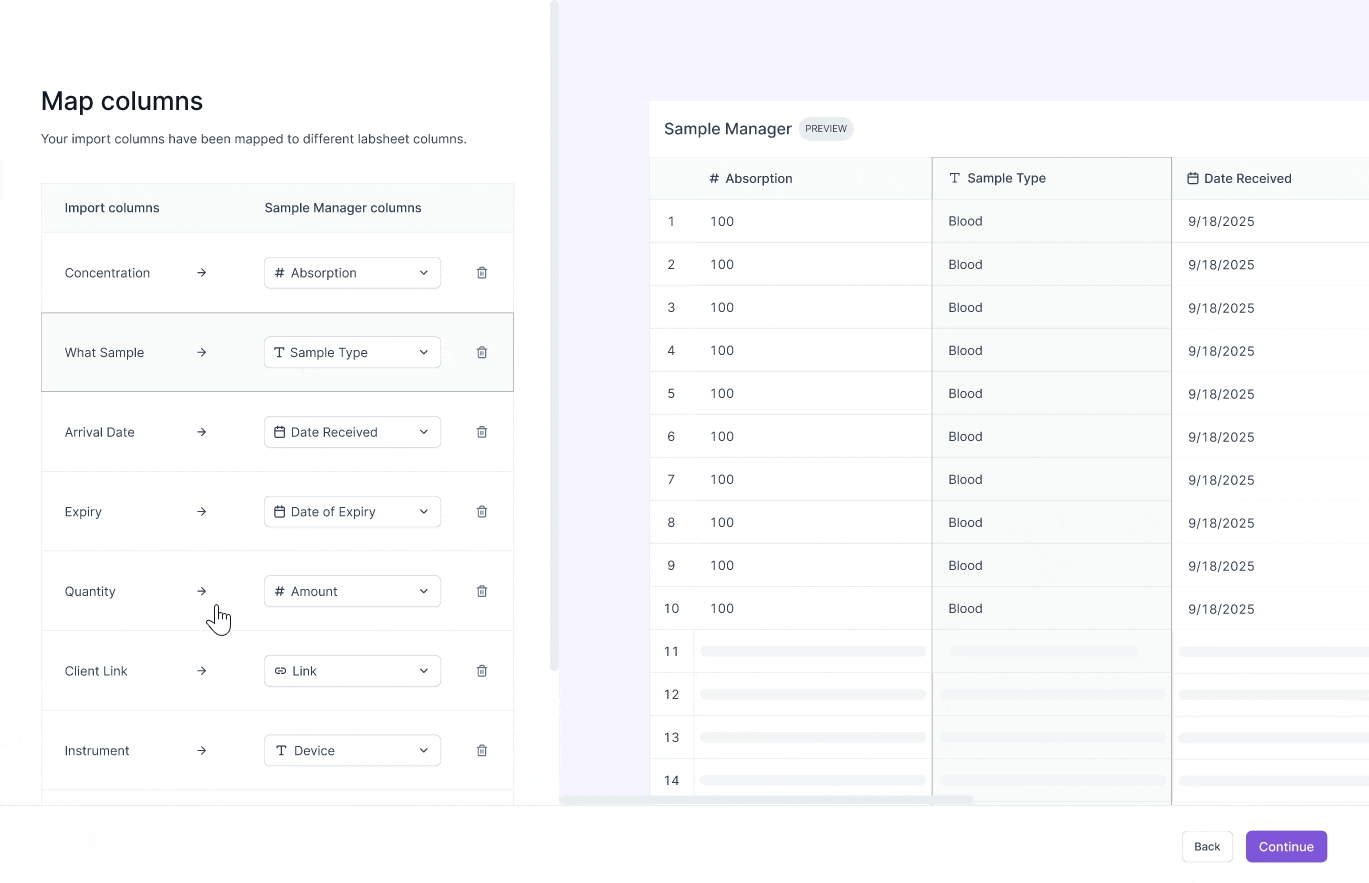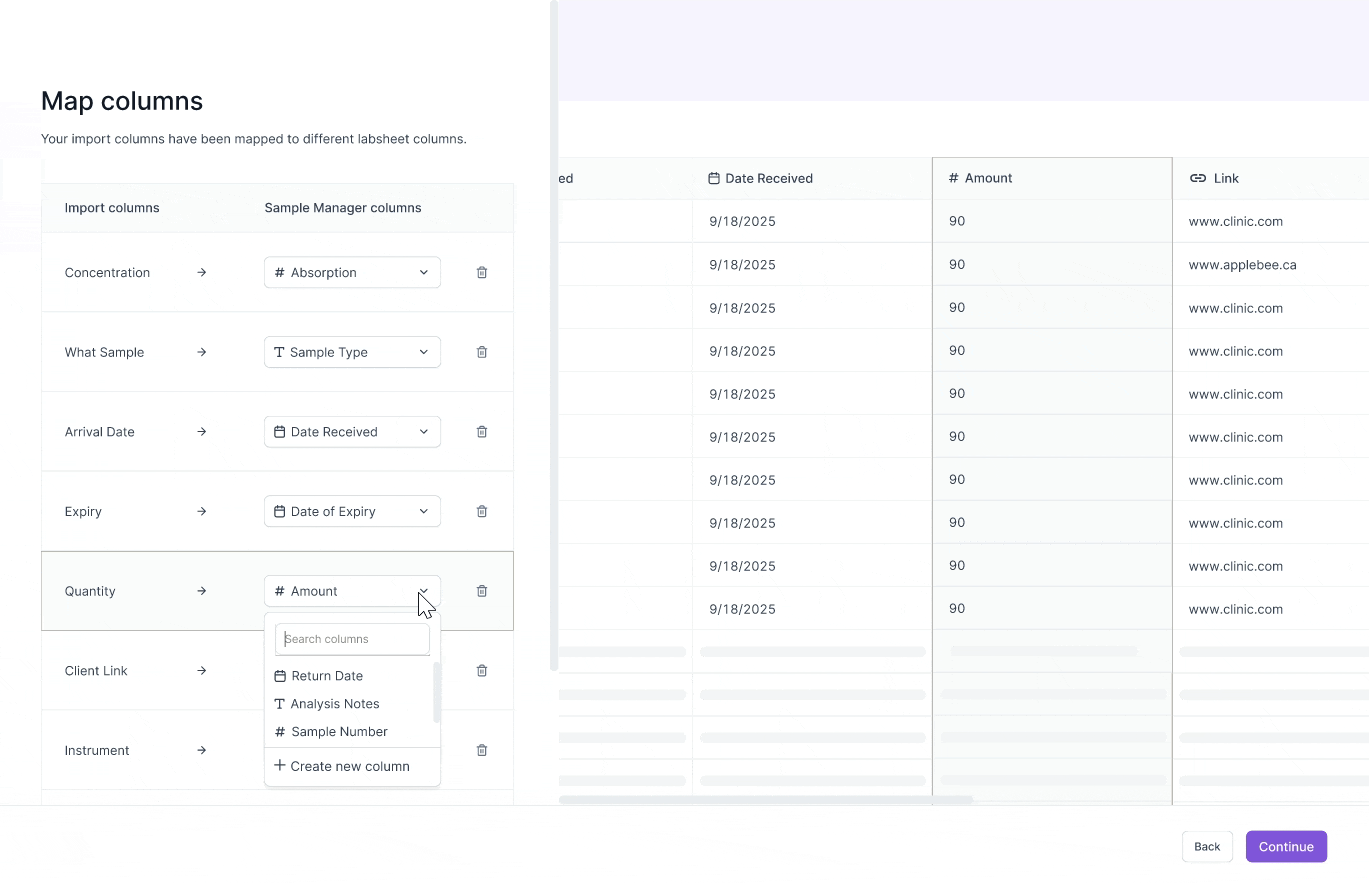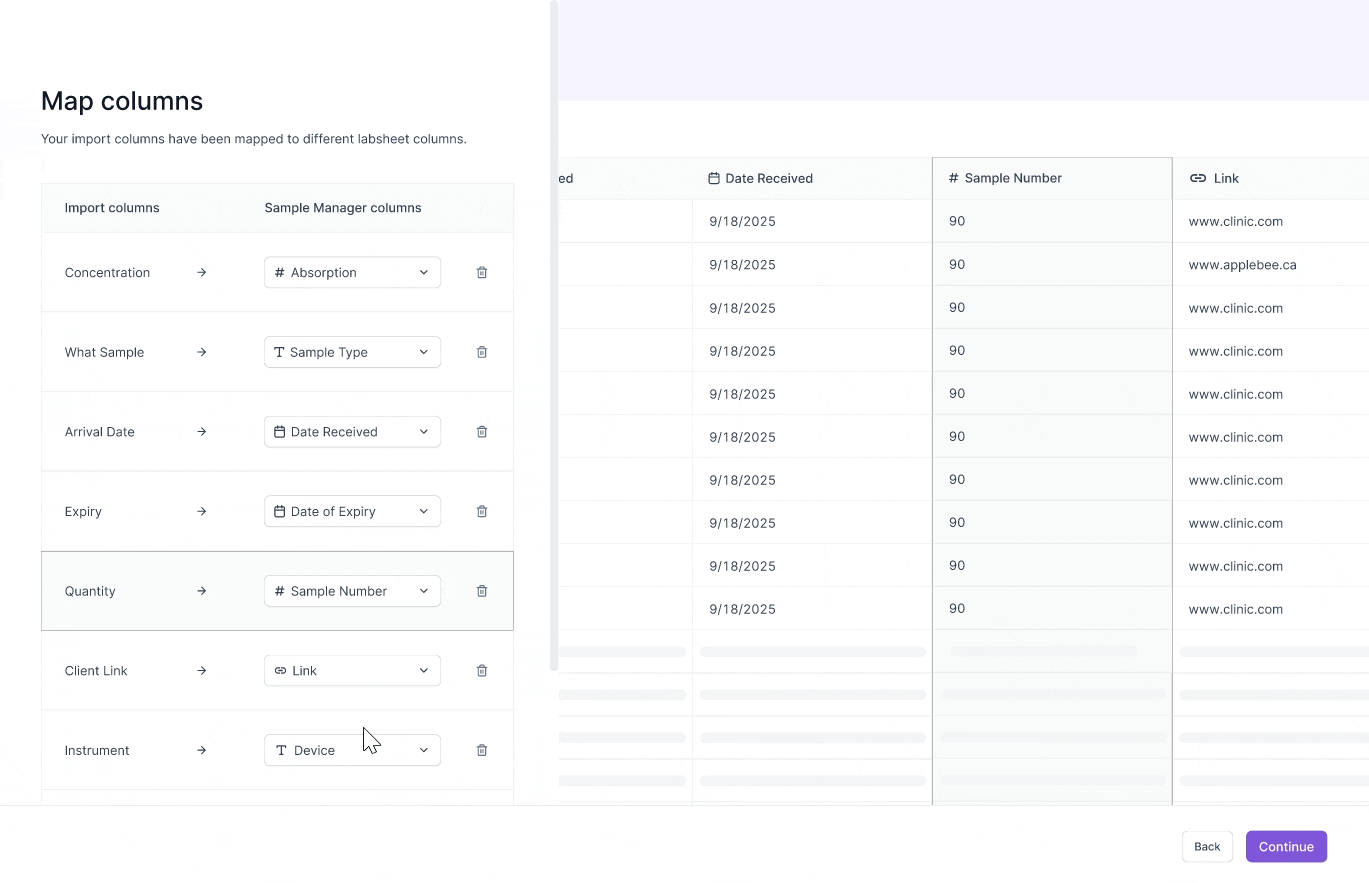
Challenge #2: Preview column mappings
Scientists have dozens of columns in their test result CSVs.
Without remembering the contents of their data, they frequently map CSV columns incorrectly to their labsheet columns.
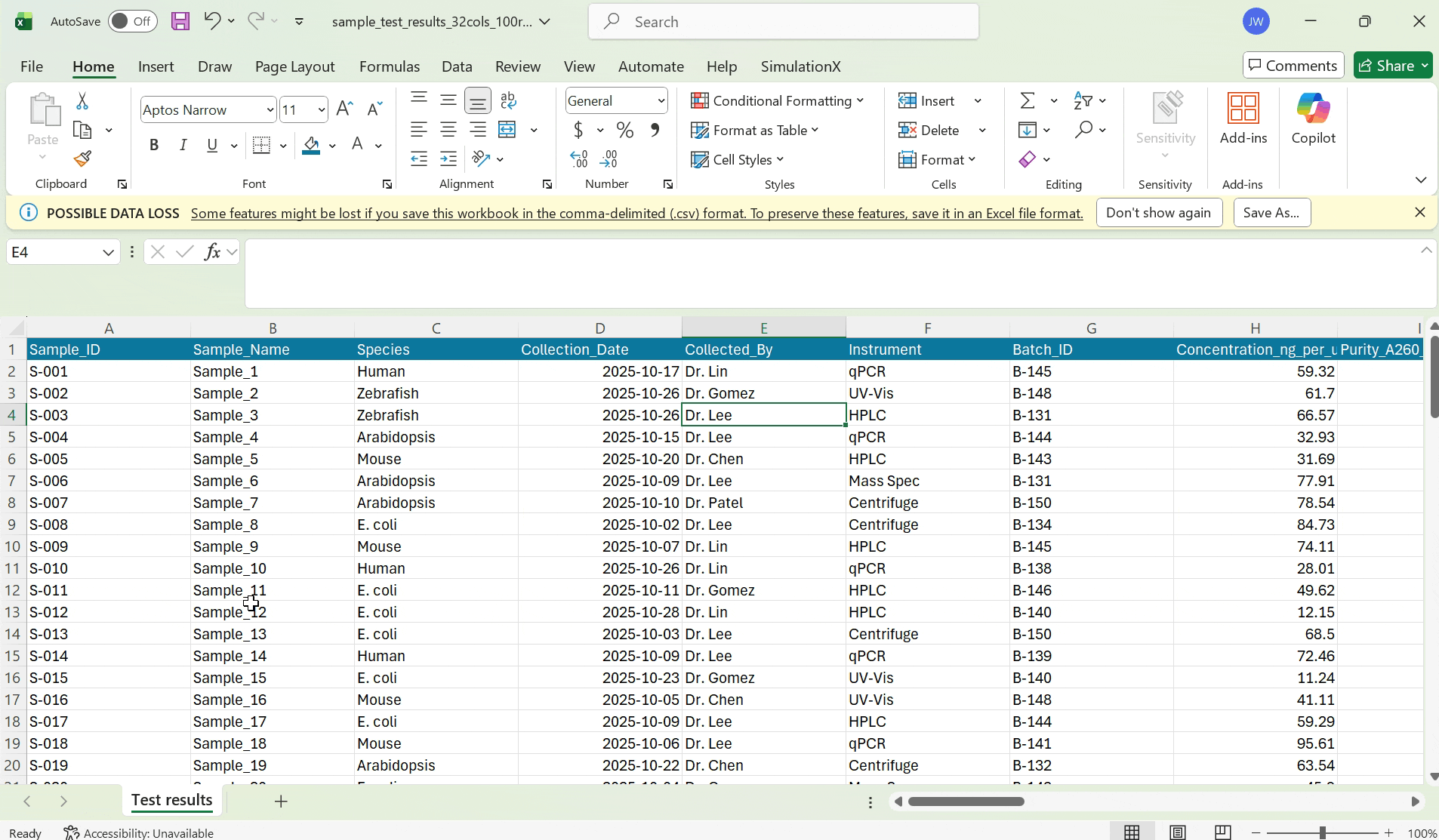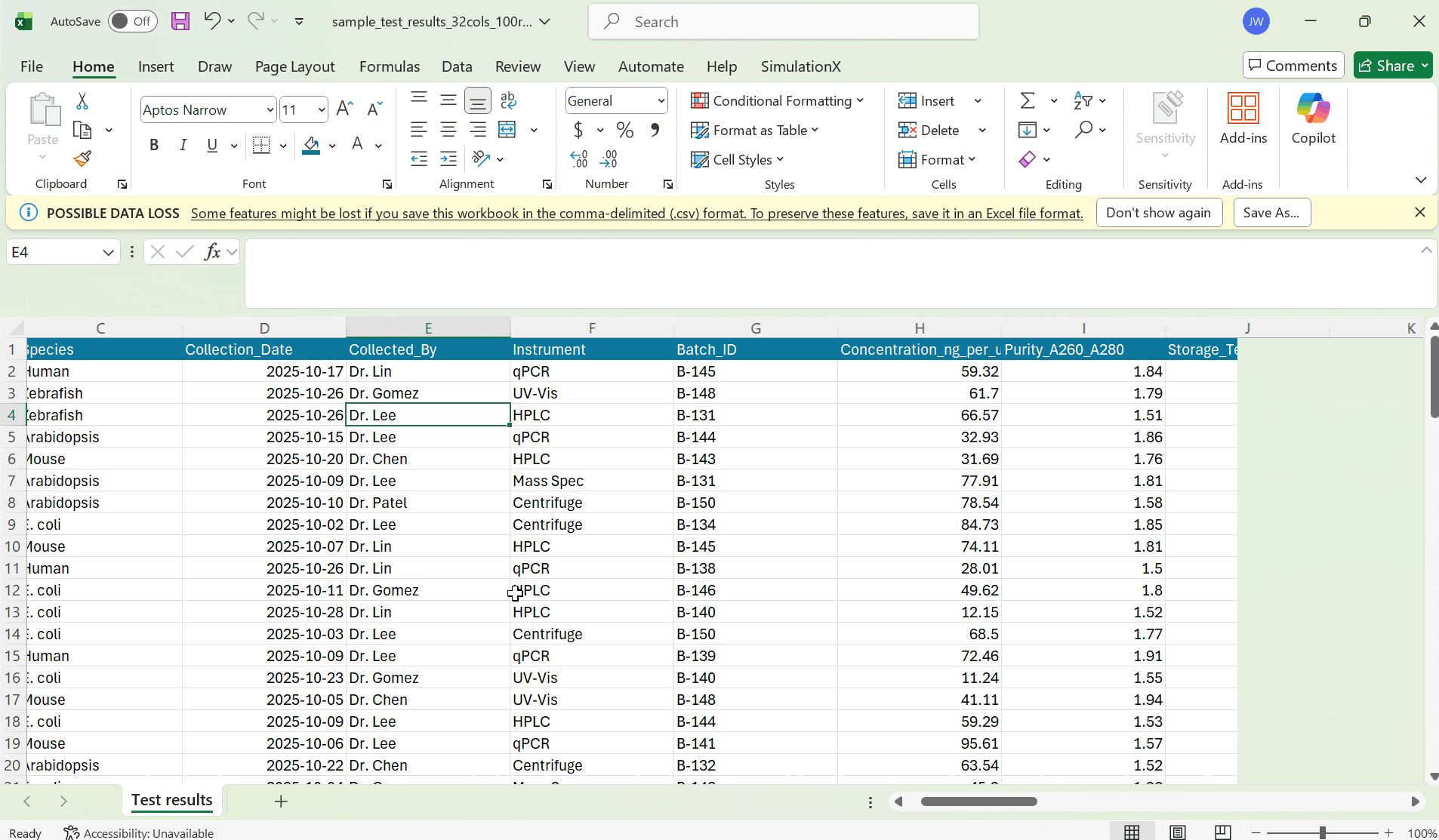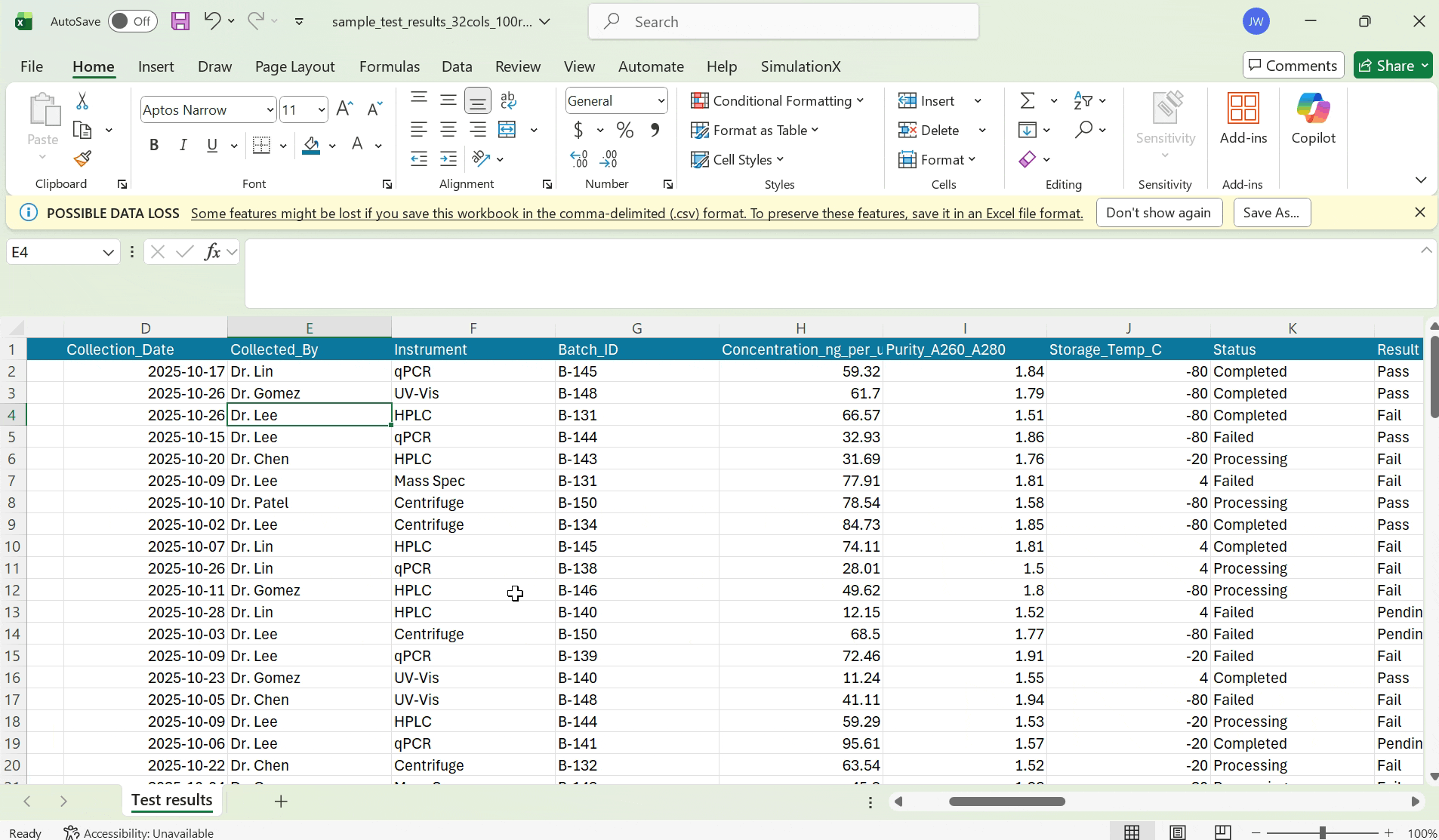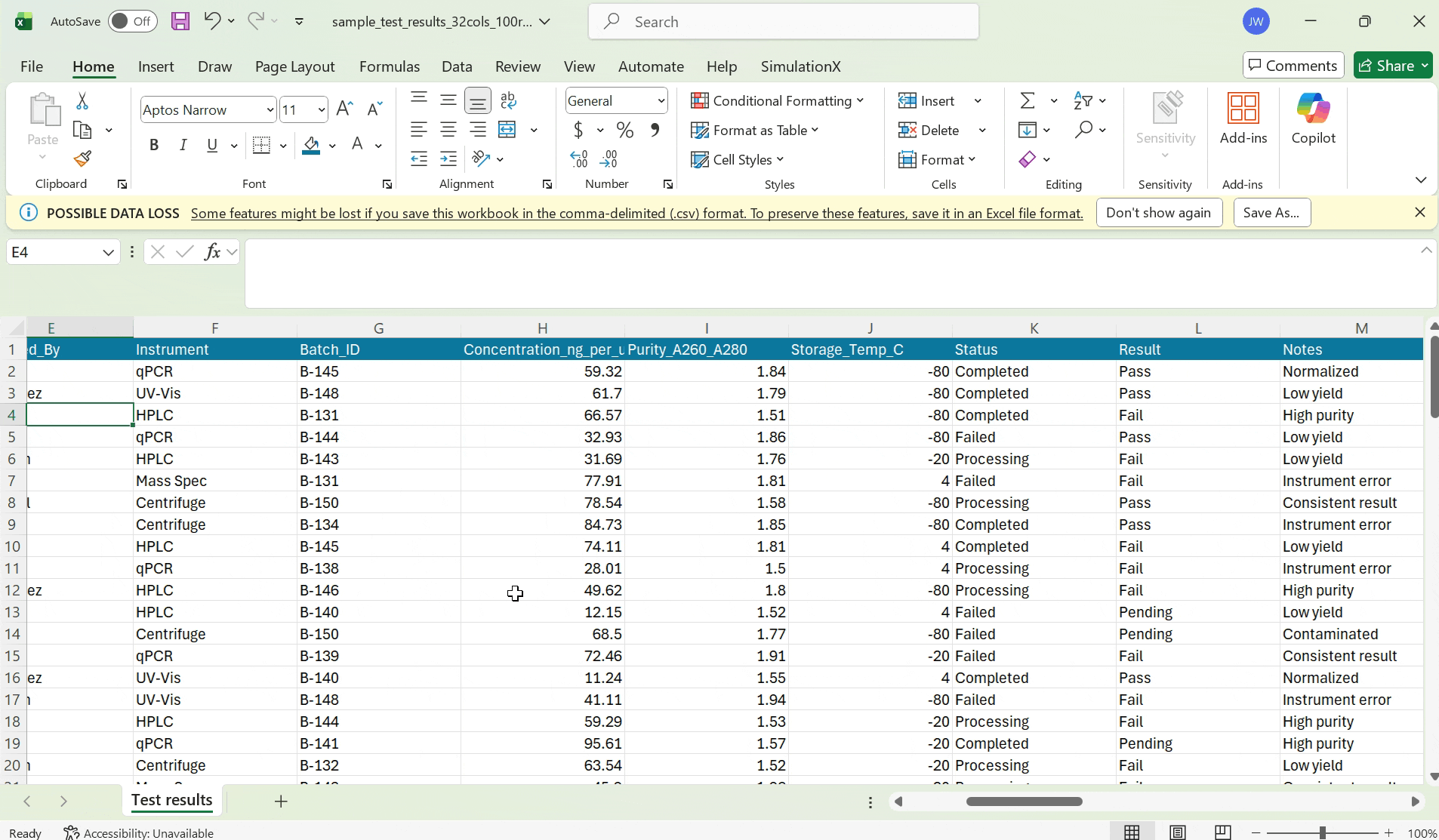
I chose to allow scientists to preview their scientific data during the mapping phase to guide their decision making.
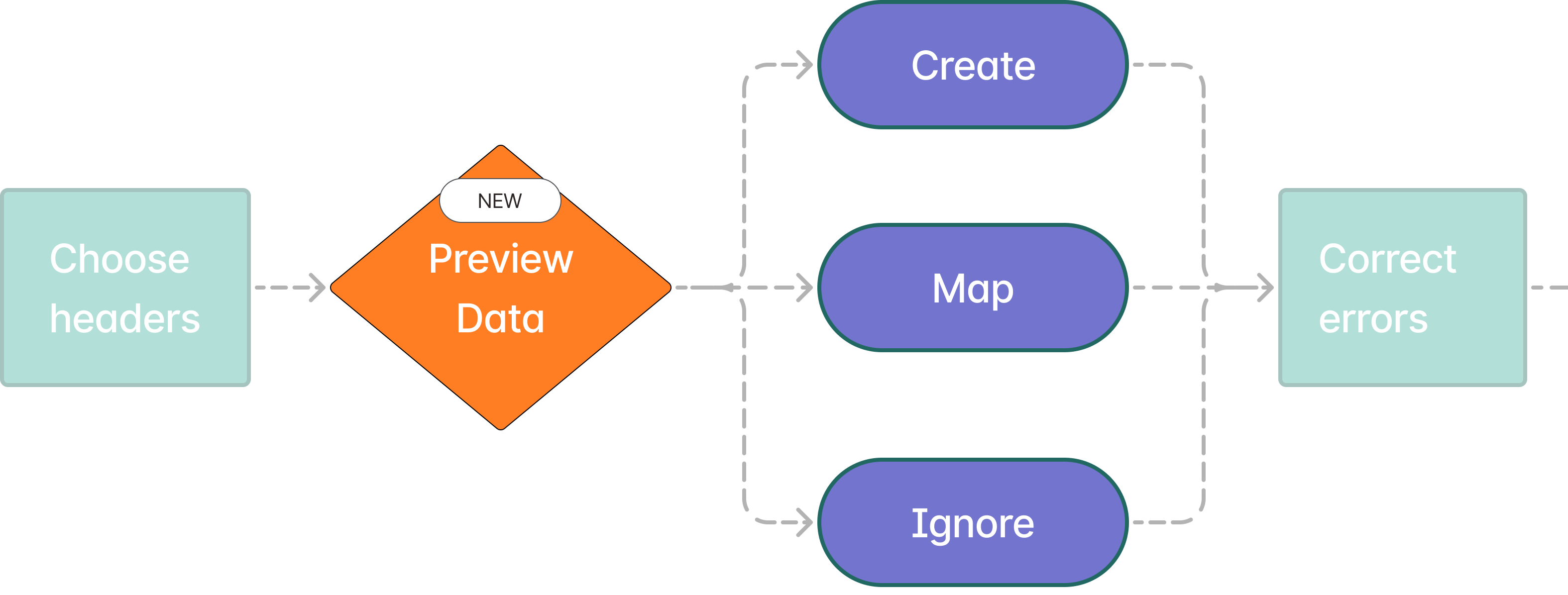
Previewing scientific csv data
I explored two designs in allowing scientists to preview their data during the mapping stage. Scientists are working with sensitive data, where even one wrong mapping can lead to a wrong test result report. So, I decided to optimize for precision for reviewing data.
VERSION 1
Optimizing for scannability
- See multiple mappings in one frame
- Easily make mistakes in reviewing data
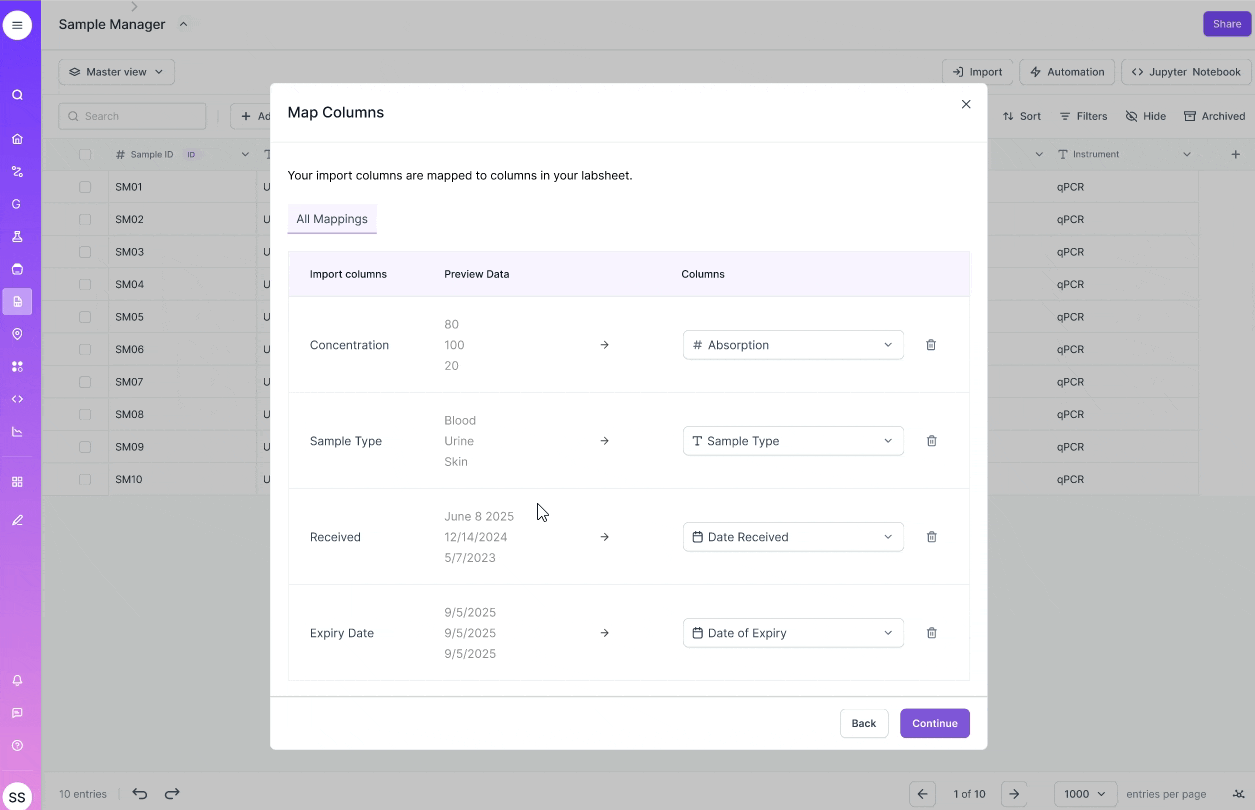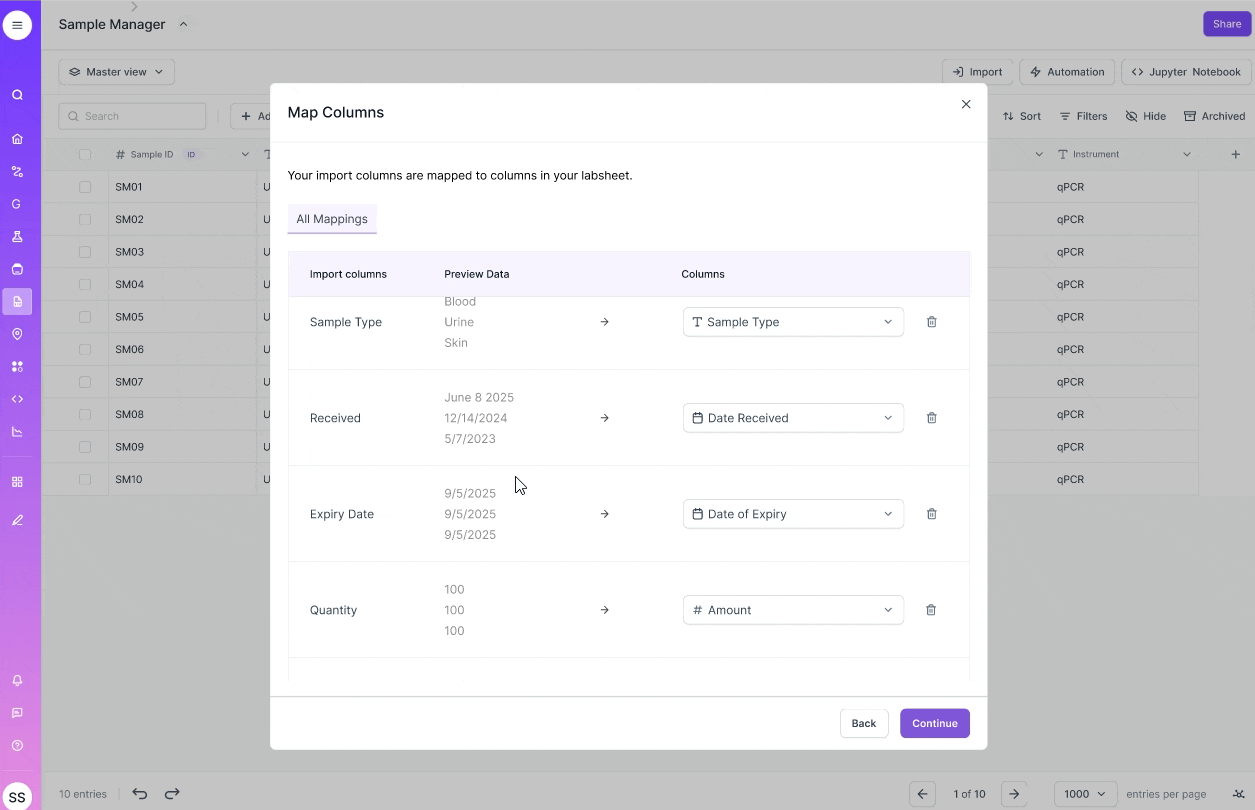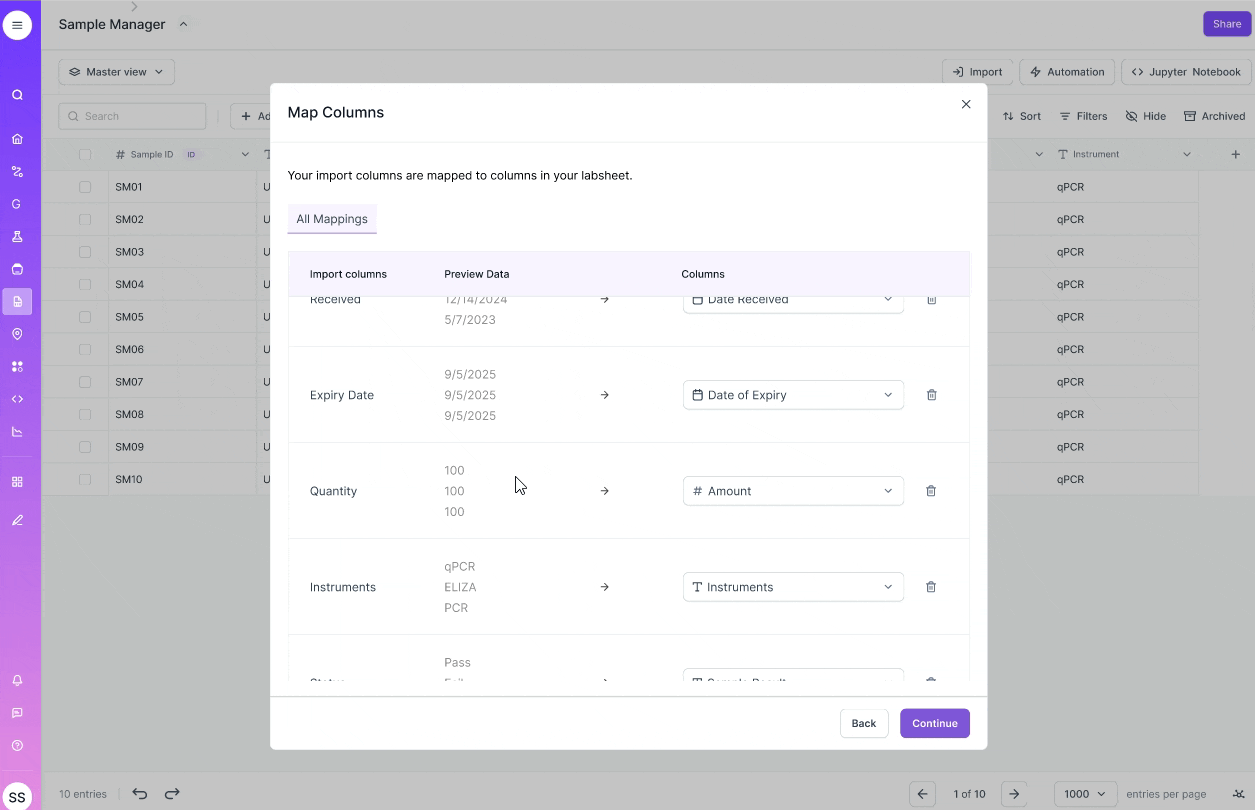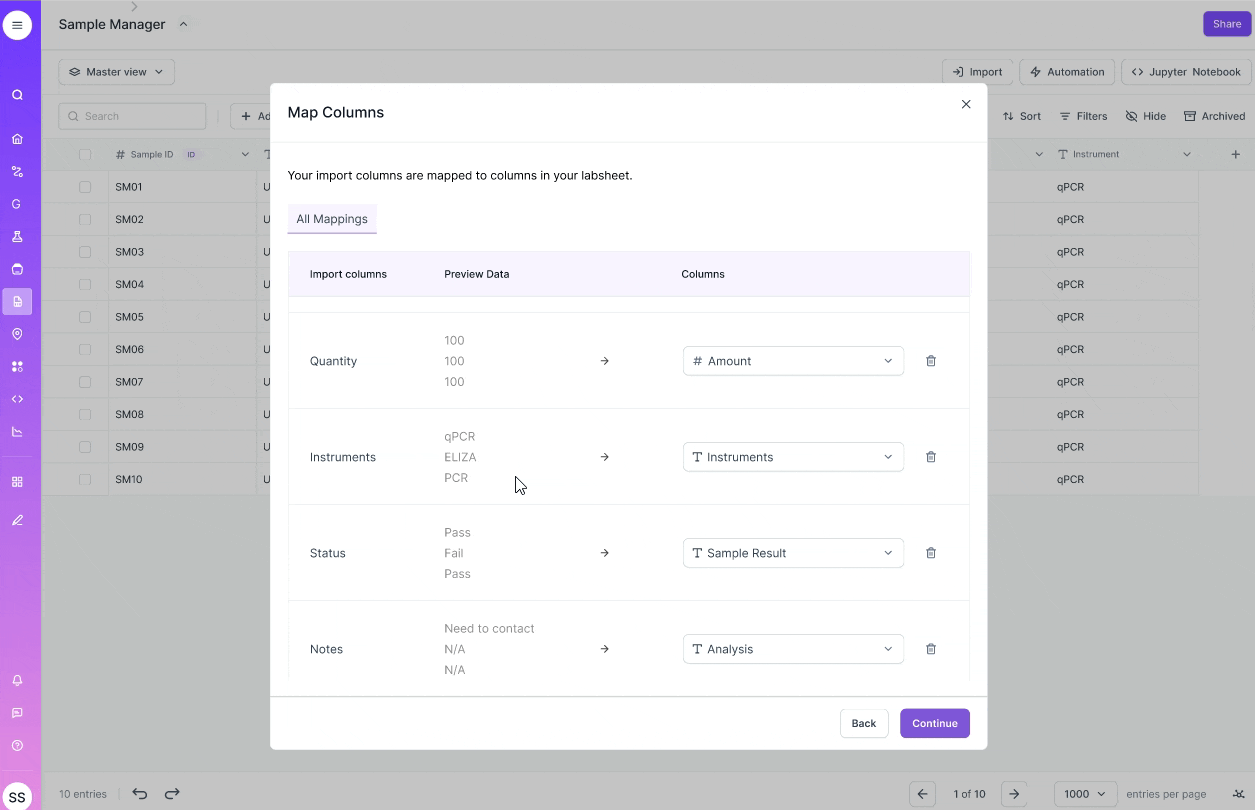
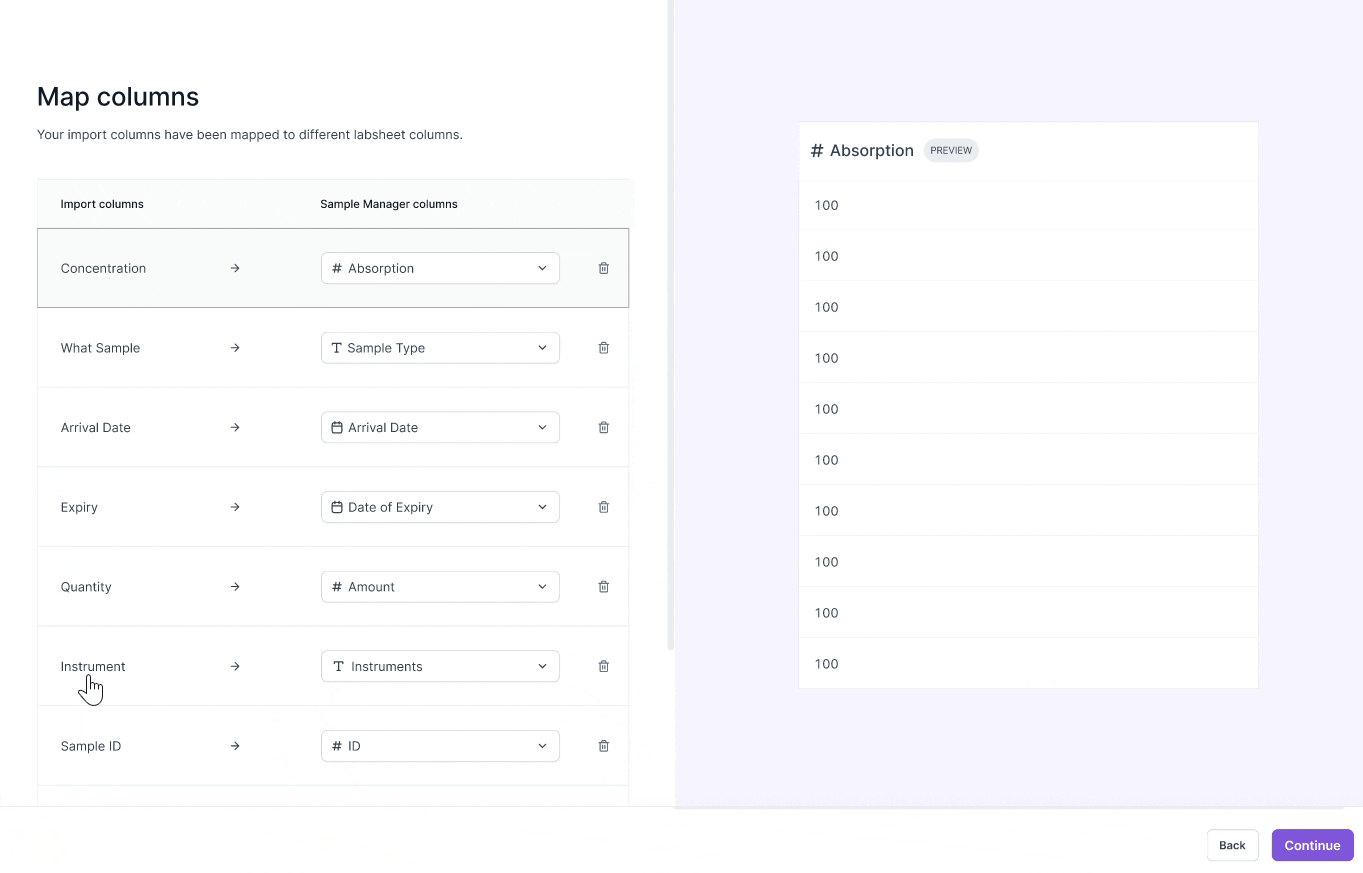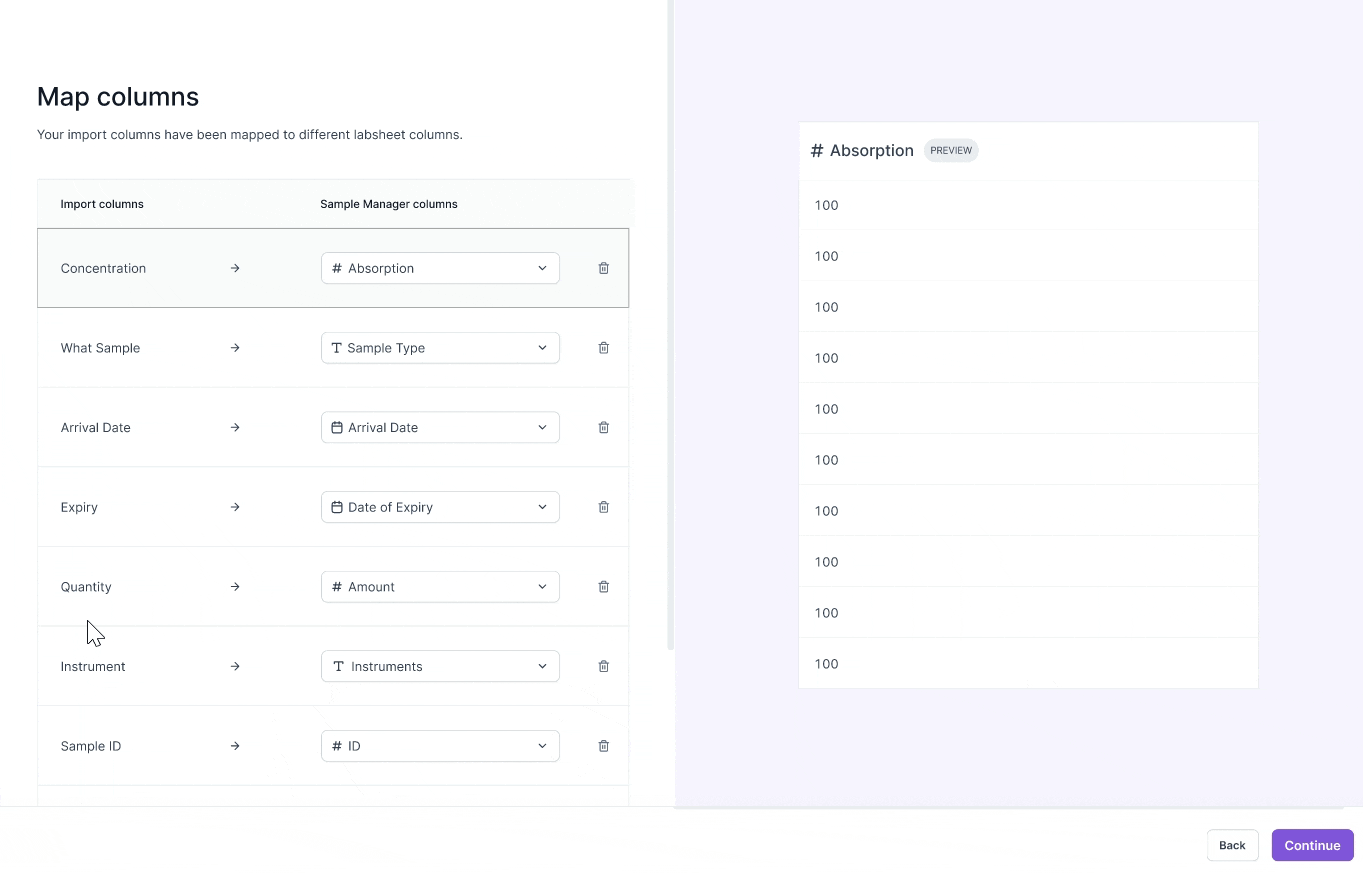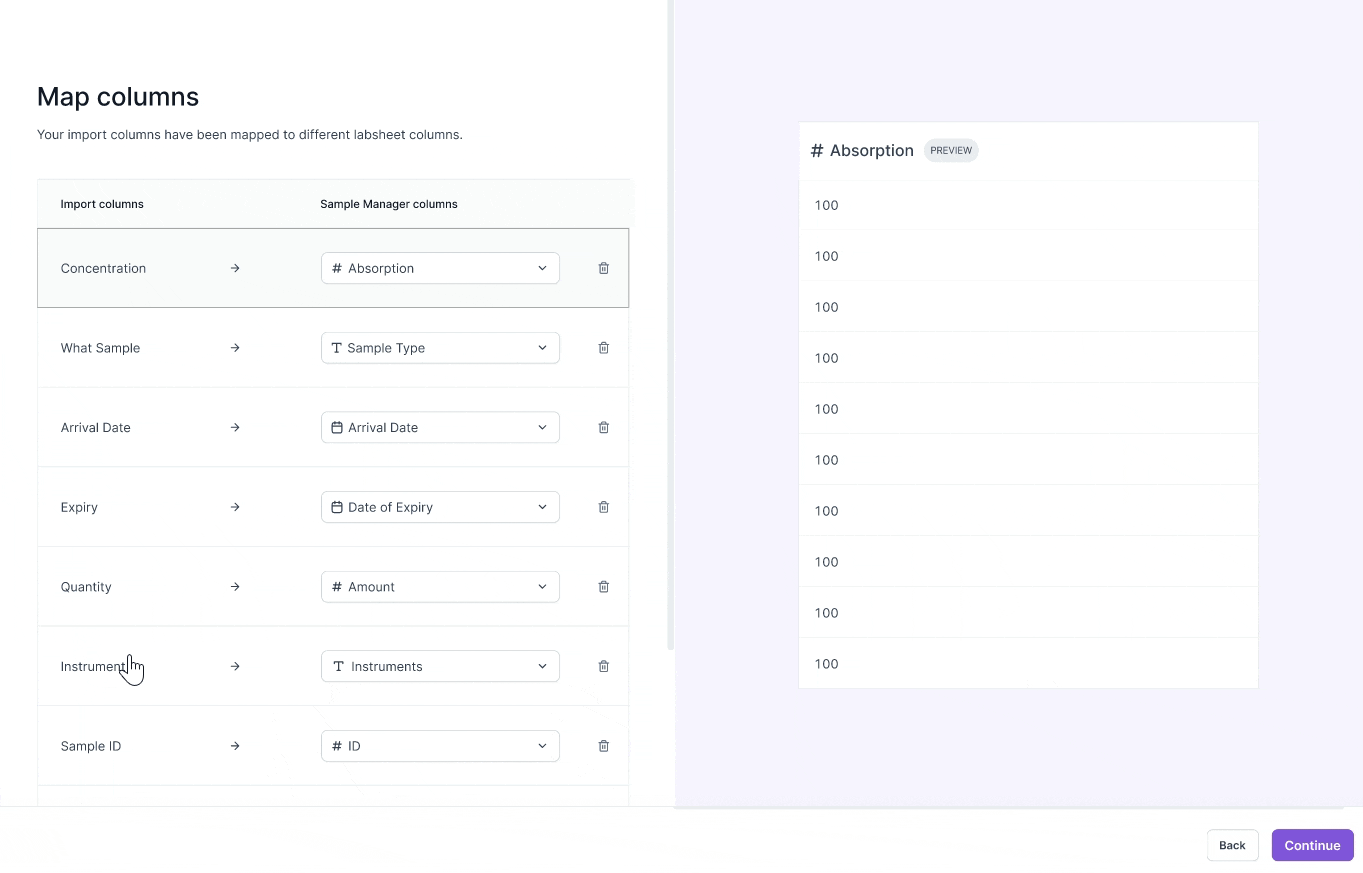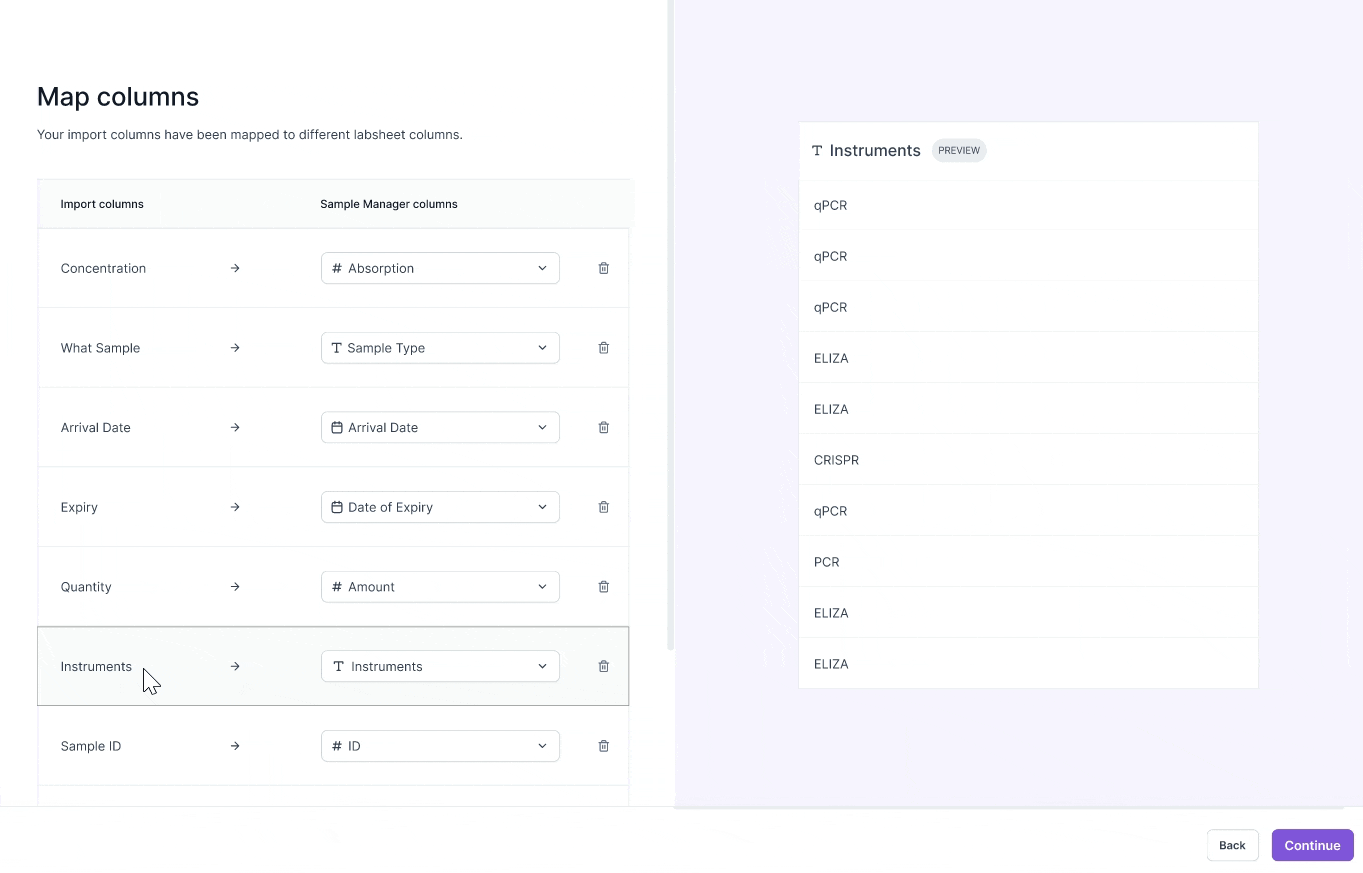
VERSION 2
Optimizing for precision
- Carefully review each data entry
- Imagine data in form factor
Currently, scientists don't know they choose to leave a csv column out of the import process.
The entry point in removing a column from import is currently mixed in with the mapping column options inside the dropdown menu.
VERSION 1
"Don't Import" dropdown option
- Hidden point of entry
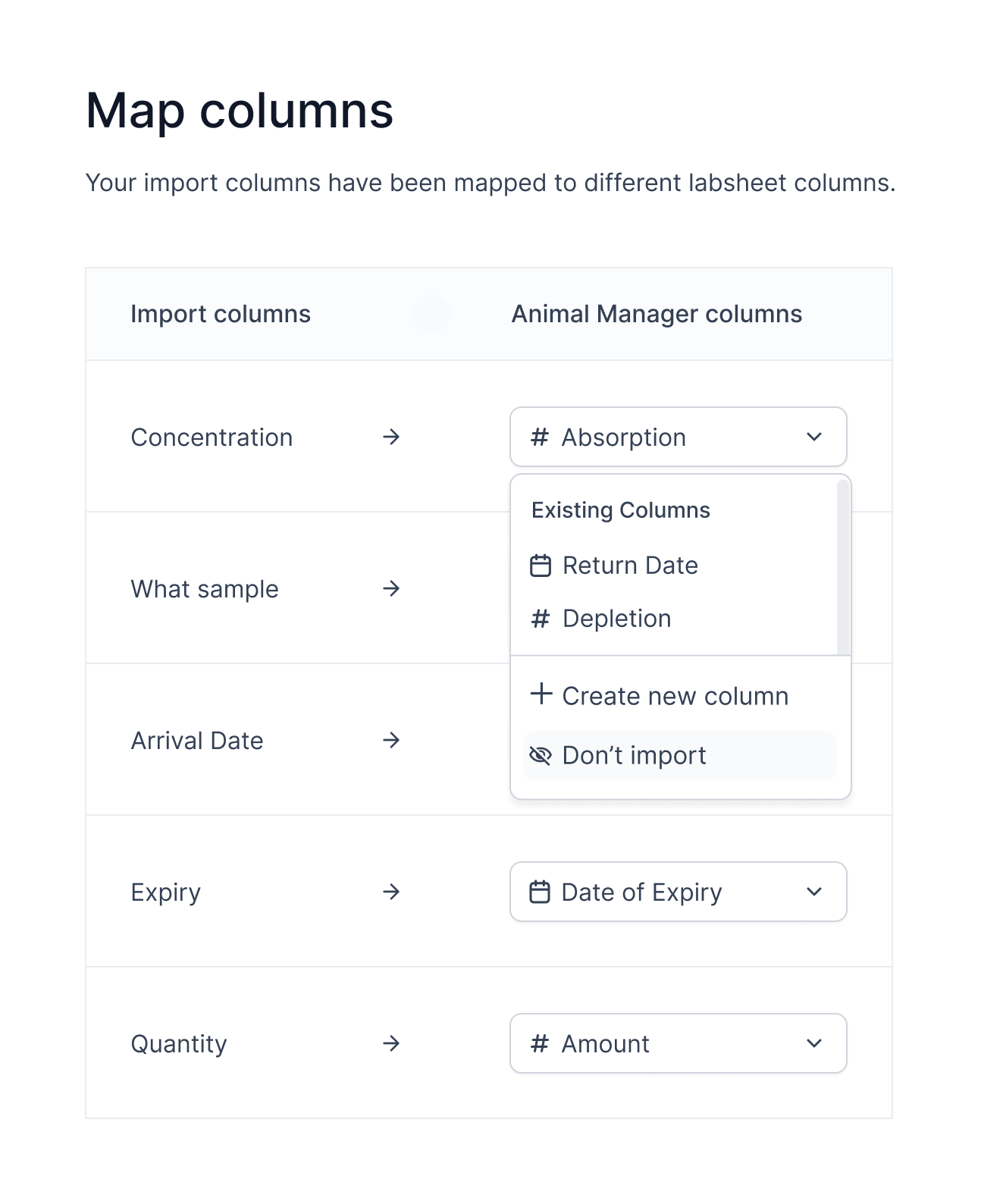
VERSION 2
Selecting columns from import
- Does not match user's mental model
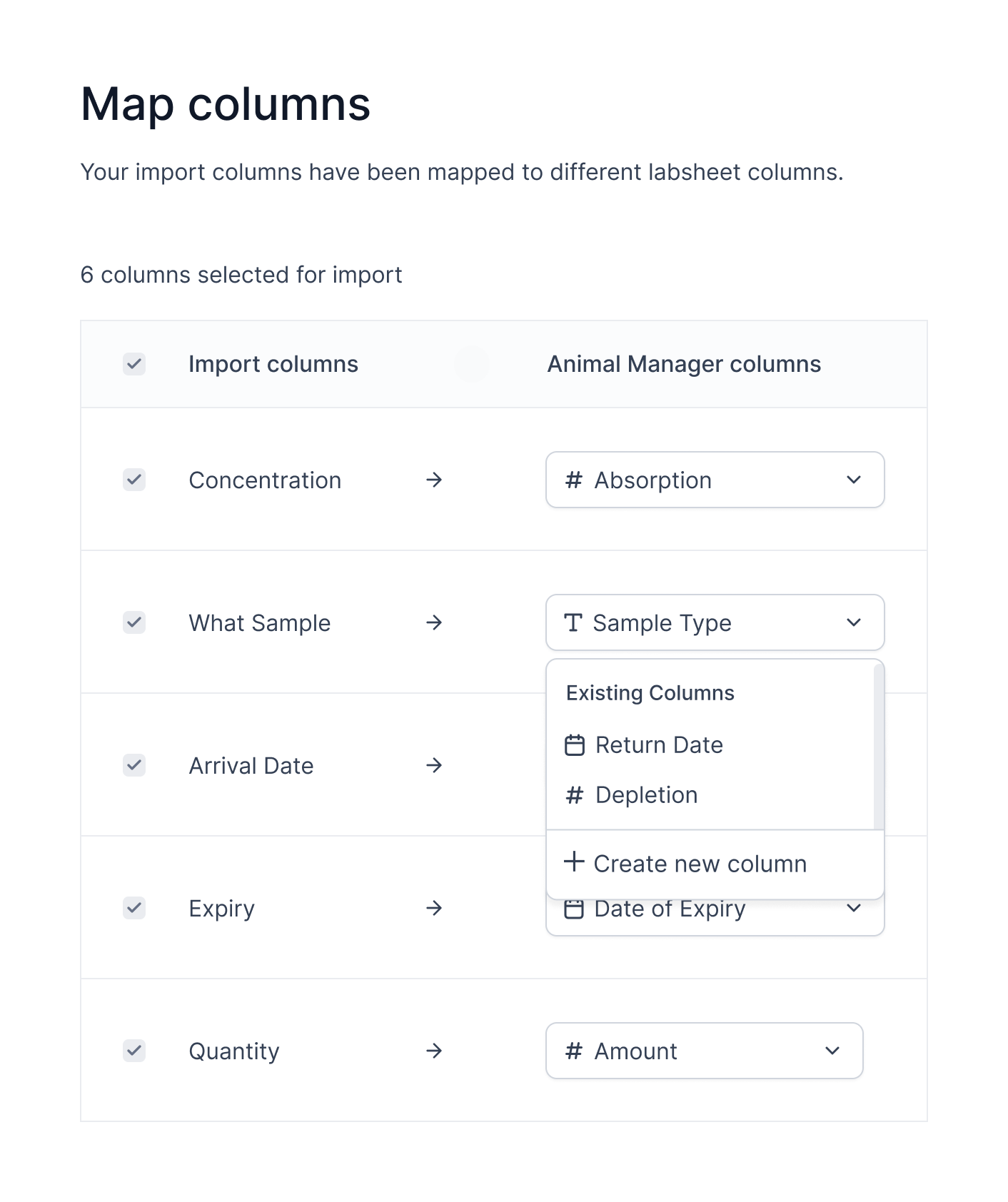
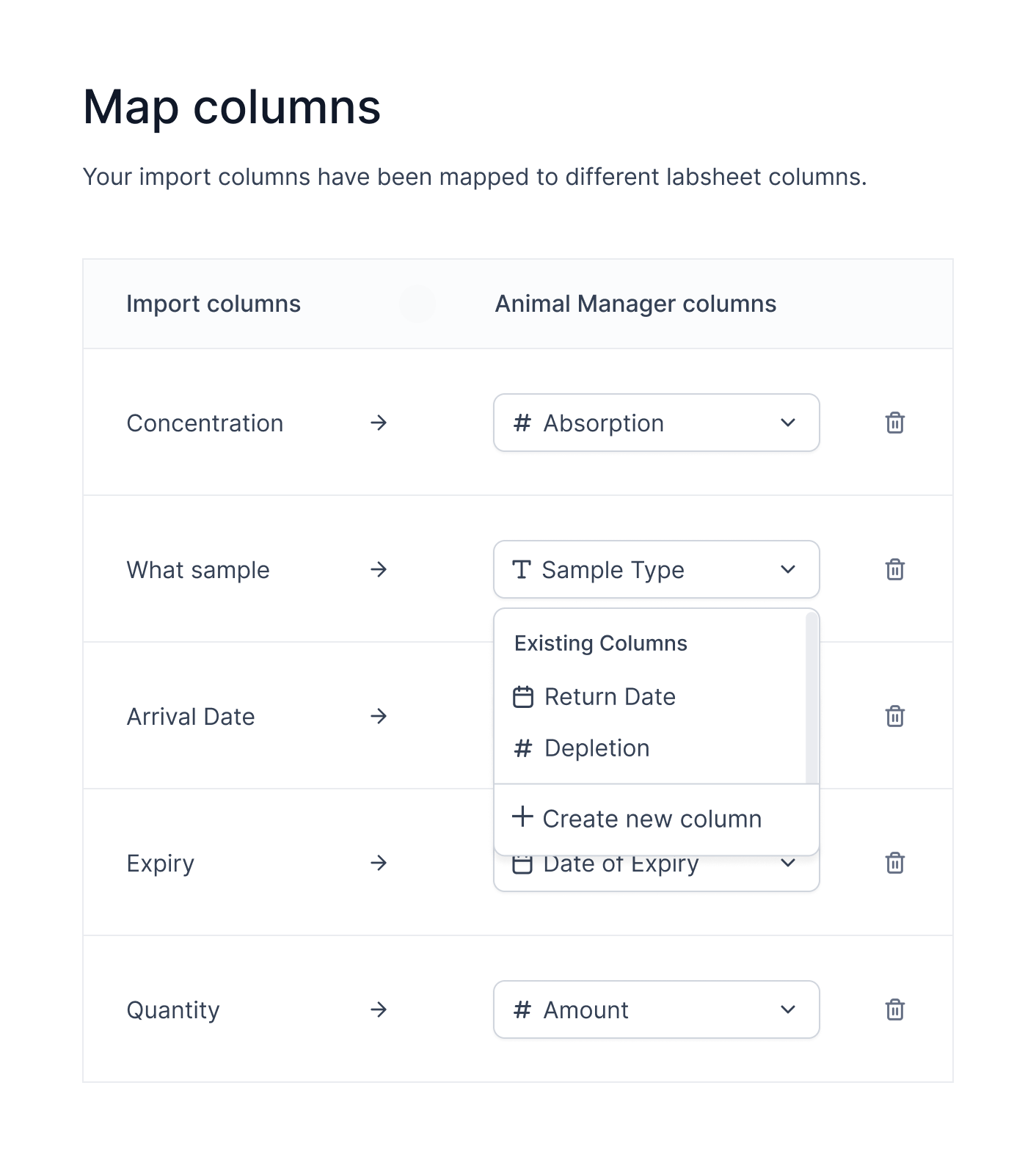
CHOSEN
Removing from import
- Top level action
- Delete icon represents a consequential action
Challenge #2: Informing Data Errors
How might we inform scientists of data incompatibilities?
Structured and clean data is incredible important for scientists to minimize error and misinterpretations during the analysis phase. Thus, I scoped out adding warnings about rows that could be lost in the import process.
VERSION 1
Pop-up error guide
- Direct users to errors throughout labsheet
- Cannot gain an overview of errors
- Visually distracting
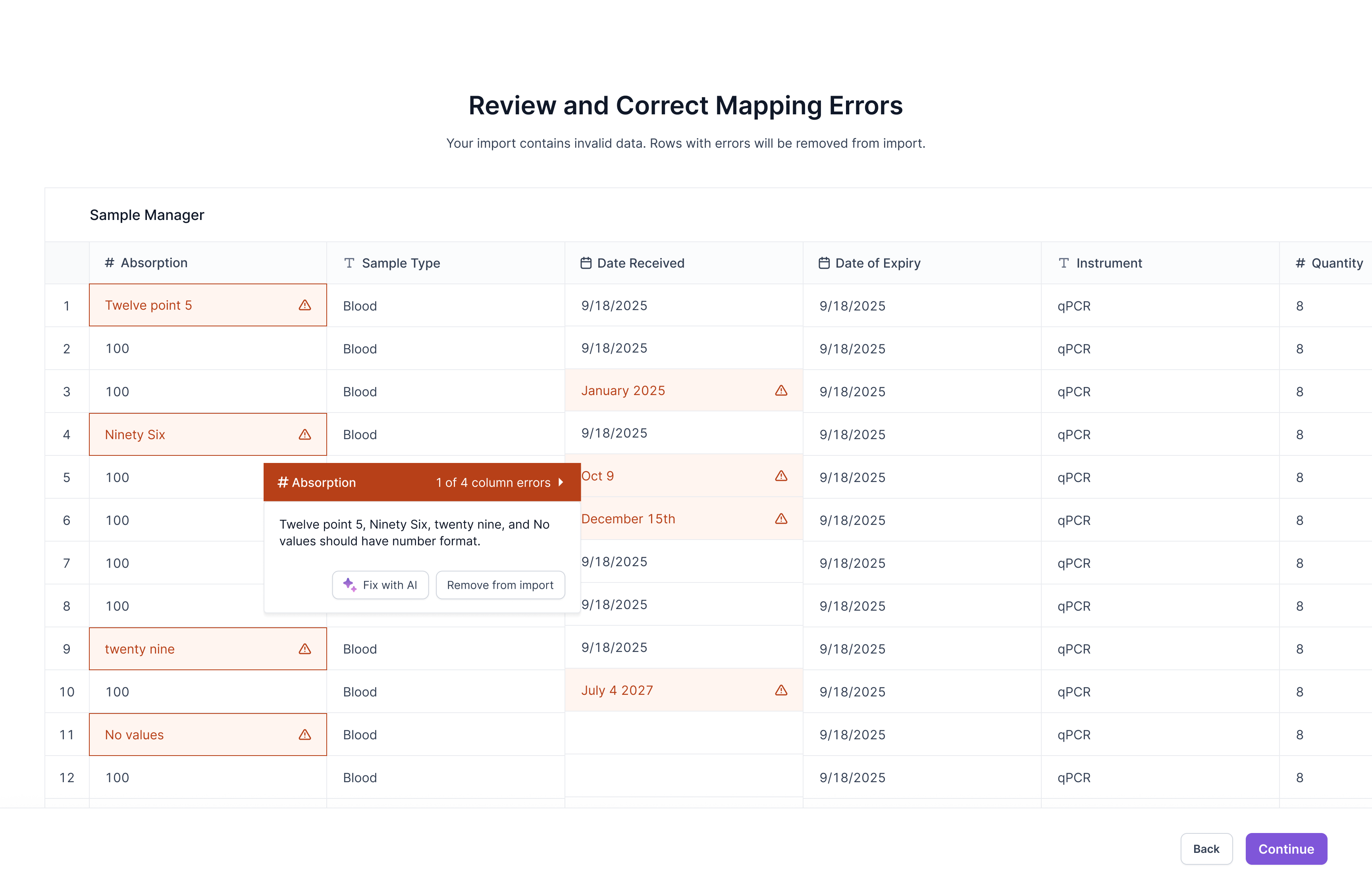
CHOSEN
Side panel of errors
- Filters rows with errors
- Clear overview and focus of all errors
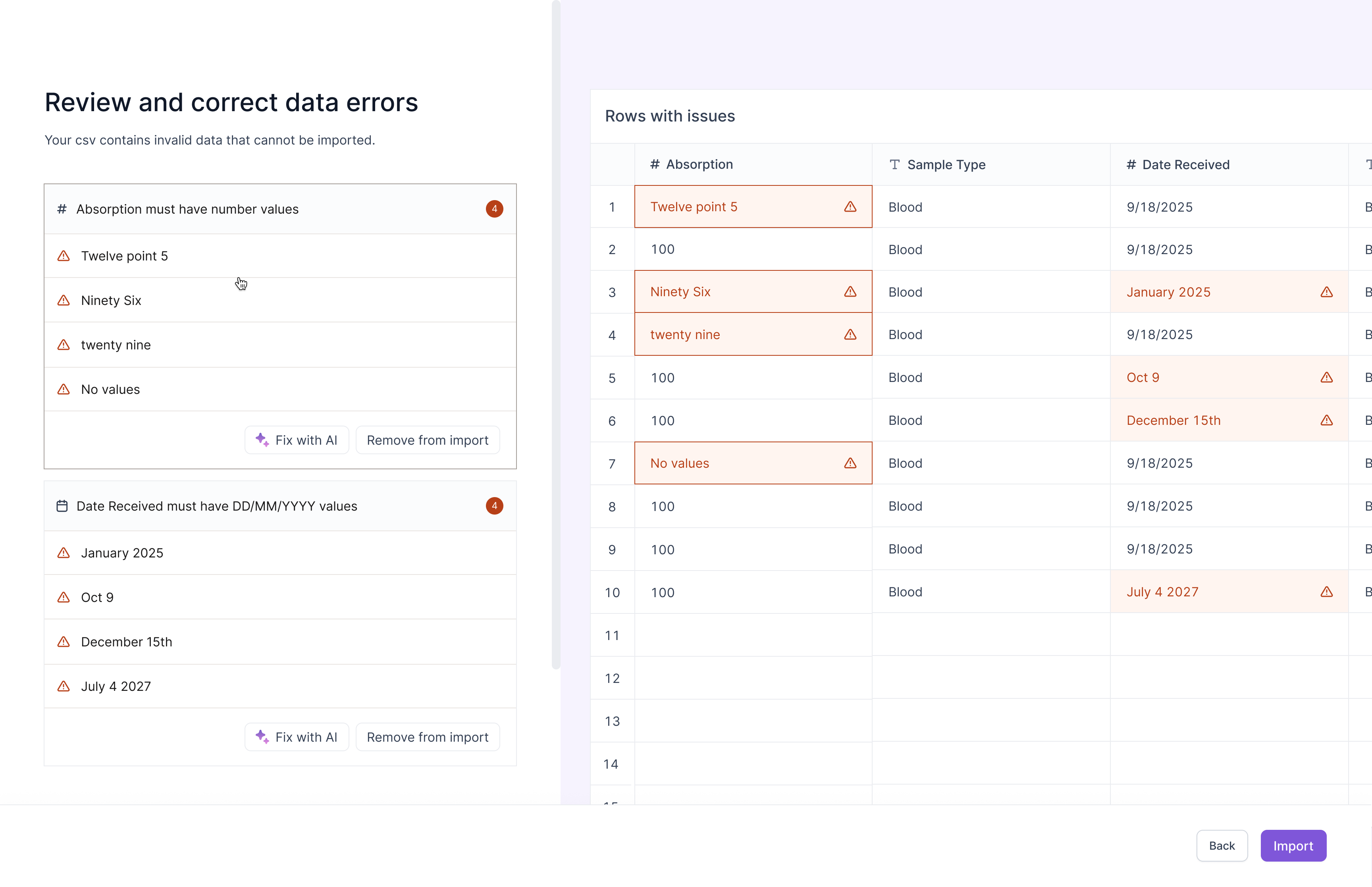
Testing & Iterations
I ran UX testing with one scientist on my team.
I gave the scientist an import csv task and asked them to try to complete the flow from start to end without any instructions. After the session, I discovered two core findings and created iterations.
FINDING
Users need to see the full data context to understand what each data entry means.
ITERATION
Added a full data preview of the spreadsheet.
FINDING
CSV files take anywhere between 2-30 minutes to upload.
ITERATION
Added a modal and toast notification to notify when users when import is completed.
.png)
Launch
We shipped version 1 of this new tool to 100+ labs.
Post-launch, we received positive response from scientists and tracked these success metrics.
Cut data import time by 30%
Resolved 90% of support tickets
Upload & setup csv columns
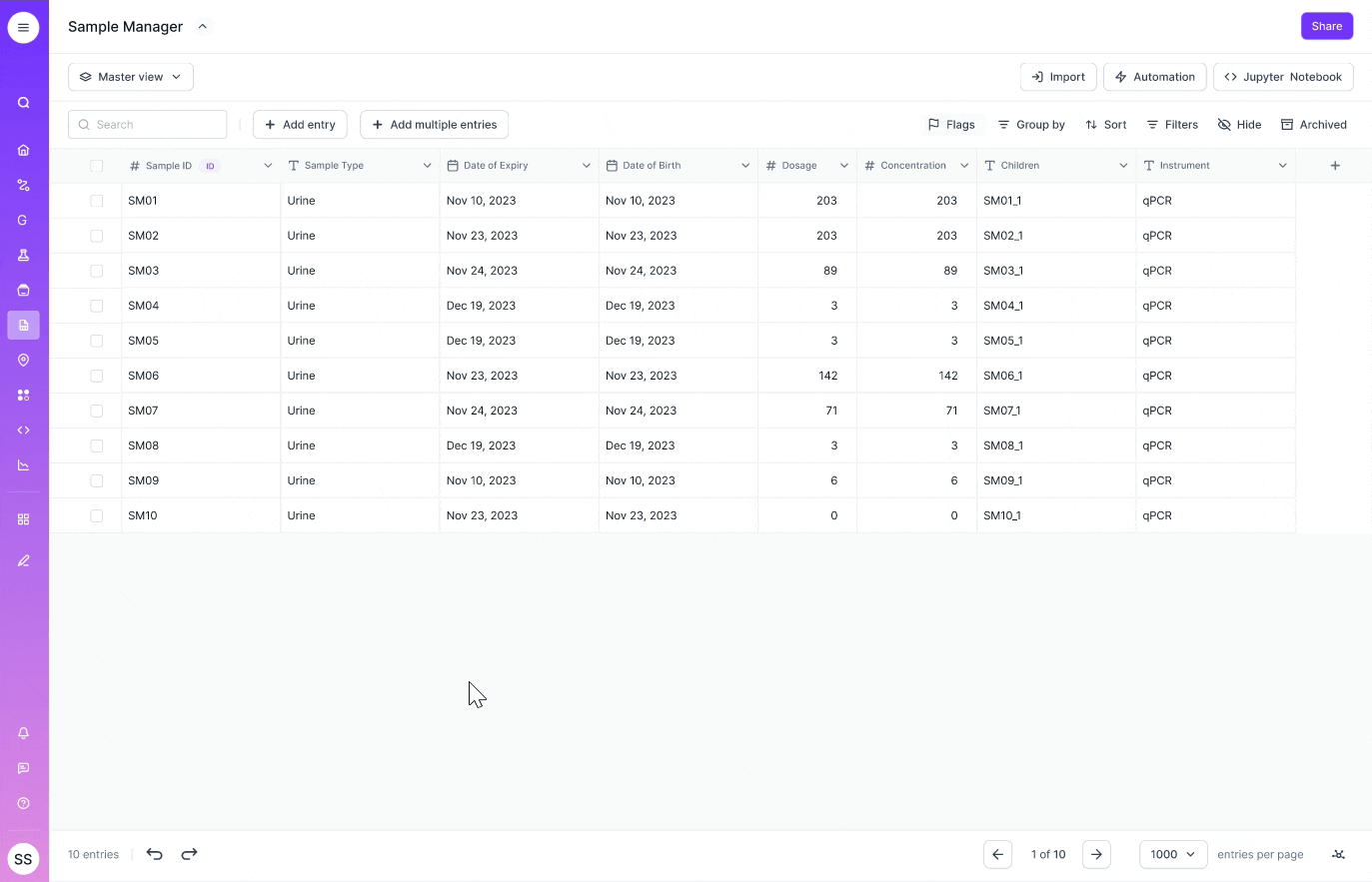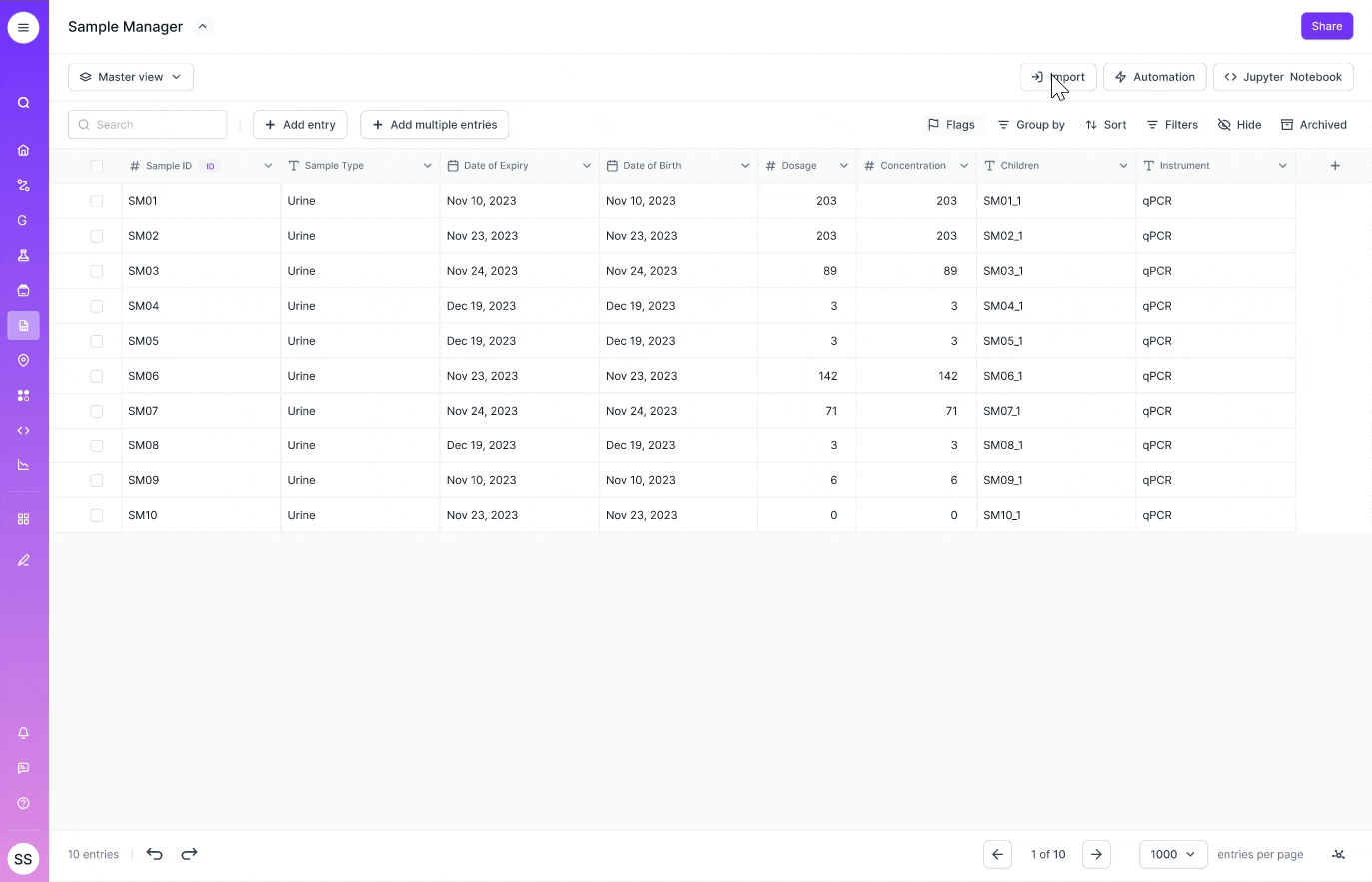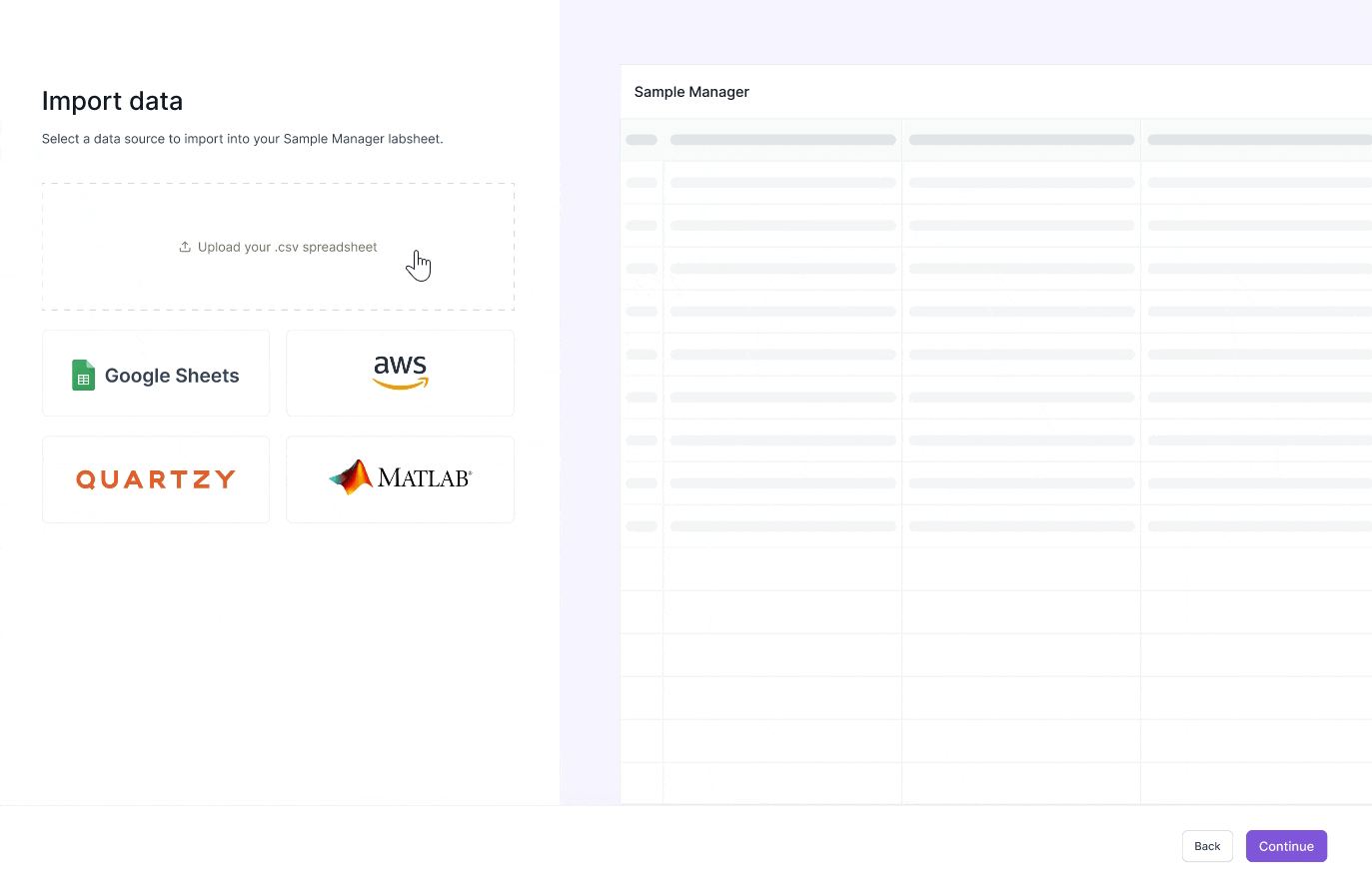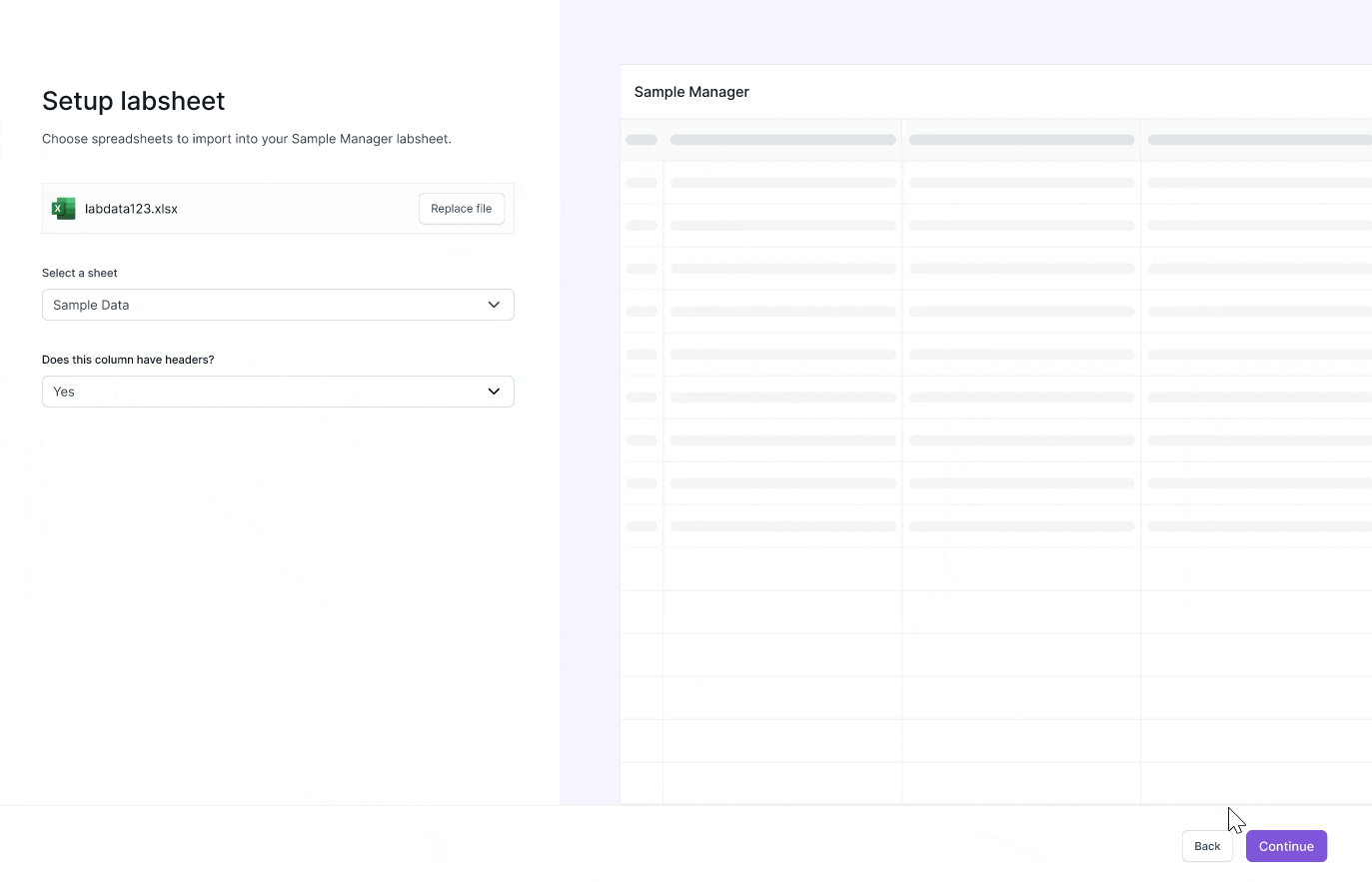
Map CSV to labsheet columns
Review and correct data errors
.gif)
Reflections
Grateful for the journey! Here's what I learned....
Quality means shipping fast
This was my first time working at a fast-paced and high-growth startup! I felt uncomfortable at first making a lot of product and design decisions at an accelerated pace. But, gradually, I learned that shipping fast and getting the design out there in the world allowed us to learn about what customers really think, get feedback, and iterate on the product, turning into something people love using.