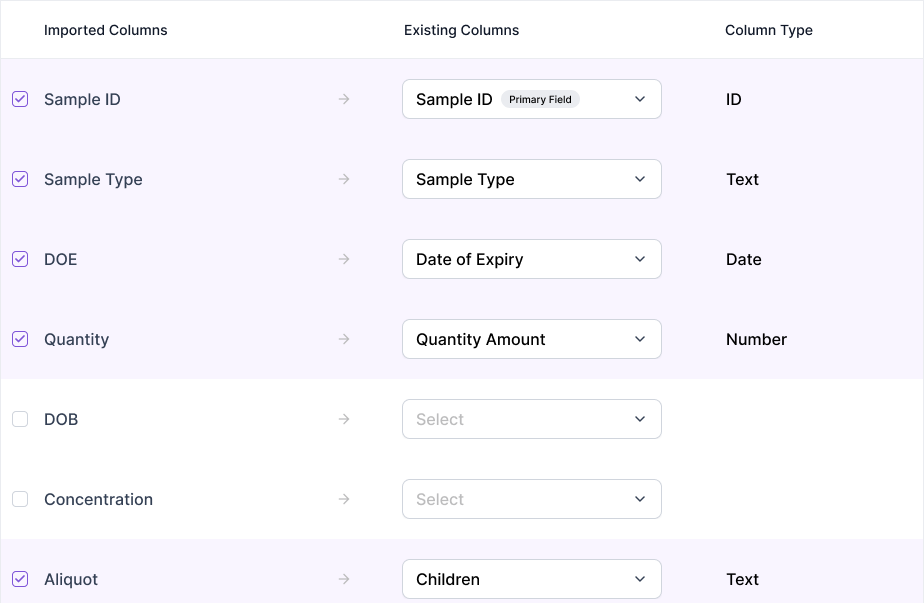
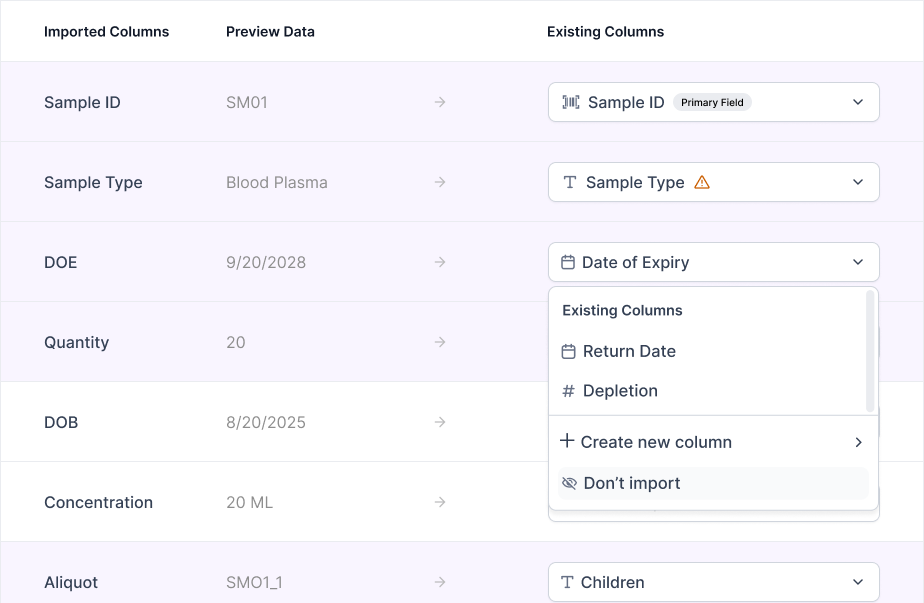
As there's a use case where scientists might not want to import a column, I created an action button where scientists can leave out columns from import. Initially in Version 1, I explored allowing scientists to check off columns. However, it was not clear that the deselected columns were not being imported. Thus in Version 2, I added a drop down menu with the "Don't Import" option.
%20(1).gif)

.png)
.png)
.png)
.png)


.png)
.png)
.jpg)
.jpg)

.png)
.png)

.png)
.png)